
Microsoft SQL Server 2005 Analysis Services Performance Guide
SQL Server Technical Article
Author: Elizabeth Vitt
Subject Matter Experts:
T.K. Anand
Sasha (Alexander) Berger
Marius Dumitru
Eric Jacobsen
Edward Melomed
Akshai Mirchandani
Mosha Pasumansky
Cristian Petculescu
Carl Rabeler
Wayne Robertson
Richard Tkachuk
Dave Wickert
Len Wyatt
Published: February 2007
Applies To: SQL Server 2005, Service Pack 2
Summary: This white paper describes how application developers can apply performance-tuning techniques to their Microsoft SQL Server 2005 Analysis Services Online Analytical Processing (OLAP) solutions.
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This White Paper is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS DOCUMENT.
Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation.
Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property.
Unless otherwise noted, the companies, organizations, products, domain names, e-mail addresses, logos, people, places, and events depicted in examples herein are fictitious. No association with any real company, organization, product, domain name, e-mail address, logo, person, place, or event is intended or should be inferred.
2007 Microsoft Corporation. All rights reserved.
Microsoft, Windows, and Windows Server
are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
All other trademarks are property of their respective owners.
Table of Contents
Introduction 6
Enhancing Query Performance 8
Understanding the querying architecture 8
Session management 9
MDX query execution 10
Data retrieval: dimensions 12
Data retrieval: measure group data 15
Optimizing the dimension design 18
Identifying attribute relationships 18
Using hierarchies effectively 22
Maximizing the value of aggregations 24
How aggregations help 24
How the Storage Engine uses aggregations 25
Why not create every possible aggregation? 27
How to interpret aggregations 29
Which aggregations are built 30
How to impact aggregation design 31
Suggesting aggregation candidates 32
Specifying statistics about cube data 36
Adopting an aggregation design strategy 39
Using partitions to enhance query performance 40
How partitions are used in querying 41
Designing partitions 41
Aggregation considerations for multiple partitions 43
Writing efficient MDX 44
Specifying the calculation space 44
Removing empty tuples 47
Summarizing data with MDX 55
Taking advantage of the Query Execution Engine cache 58
Applying calculation best practices 60
Tuning Processing Performance 61
Understanding the processing architecture 61
Processing job overview 61
Dimension processing jobs 62
Dimension-processing commands 64
Partition-processing jobs 65
Partition-processing commands 65
Executing processing jobs 66
Refreshing dimensions efficiently 67
Optimizing the source query 67
Reducing attribute overhead 68
Optimizing dimension inserts, updates, and deletes 70
Refreshing partitions efficiently 71
Optimizing the source query 71
Using partitions to enhance processing performance 72
Optimizing data inserts, updates, and deletes 72
Evaluating rigid vs. flexible aggregations 73
Optimizing Special Design Scenarios 76
Special aggregate functions 76
Optimizing distinct count 76
Optimizing semiadditive measures 78
Parent-child hierarchies 79
Complex dimension relationships 79
Many-to-many relationships 80
Reference relationships 82
Near real-time data refreshes 86
Tuning Server Resources 91
Understanding how Analysis Services uses memory 92
Memory management 92
Shrinkable vs. non-shrinkable memory 94
Memory demands during querying 95
Memory demands during processing 96
Optimizing memory usage 97
Increasing available memory 97
Monitoring memory management 97
Minimizing metadata overhead 98
Monitoring the timeout of idle sessions 99
Tuning memory for partition processing 100
Warming the data cache 101
Understanding how Analysis Services uses CPU resources 103
Job architecture 103
Thread pools 103
Processor demands during querying 104
Processor demands during processing 104
Optimizing CPU usage 105
Maximize parallelism during querying 105
Maximize parallelism during processing 107
Use sufficient memory 109
Use a load-balancing cluster 109
Understanding how Analysis Services uses disk resources 110
Disk resource demands during processing 110
Disk resource demands during querying 110
Optimizing disk usage 111
Using sufficient memory 111
Optimizing file locations 111
Disabling unnecessary logging 111
Conclusion 112
Appendix A – For More Information 113
Appendix B – Partition Storage Modes 113
Multidimensional OLAP (MOLAP) 113
Hybrid OLAP (HOLAP) 114
Relational OLAP (ROLAP) 115
Appendix C – Aggregation Utility 116
Benefits of the Aggregation Utility 116
How the Aggregation Utility organizes partitions 117
How the Aggregation Utility works 118
Introduction
Fast query response times and timely data refresh are two well-established performance requirements of Online Analytical Processing (OLAP) systems. To provide fast analysis, OLAP systems traditionally use hierarchies to efficiently organize and summarize data. While these hierarchies provide structure and efficiency to analysis, they tend to restrict the analytic freedom of end users who want to freely analyze and organize data on the fly.
To support a broad range of structured and flexible analysis options, Microsoft® SQL Server™ Analysis Services (SSAS) 2005 combines the benefits of traditional hierarchical analysis with the flexibility of a new generation of attribute hierarchies. Attribute hierarchies allow users to freely organize data at query time, rather than being limited to the predefined navigation paths of the OLAP architect. To support this flexibility, the Analysis Services OLAP architecture is specifically designed to accommodate both attribute and hierarchical analysis while maintaining the fast query performance of conventional OLAP databases.
Realizing the performance benefits of this combined analysis paradigm requires understanding how the OLAP architecture supports both attribute hierarchies and traditional hierarchies, how you can effectively use the architecture to satisfy your analysis requirements, and how you can maximize the architecture’s utilization of system resources.
Note To apply the performance tuning techniques discussed in this white paper, you must have SQL Server 2005 Service Pack 2 installed.
To satisfy the performance needs of various OLAP designs and server environments, this white paper provides extensive guidance on how you can take advantage of the wide range of opportunities to optimize Analysis Services performance. Since Analysis Services performance tuning is a fairly broad subject, this white paper organizes performance tuning techniques into the following four segments.
Enhancing Query Performance – Query performance directly impacts the quality of the end user experience. As such, it is the primary benchmark used to evaluate the success of an OLAP implementation. Analysis Services provides a variety of mechanisms to accelerate query performance, including aggregations, caching, and indexed data retrieval. In addition, you can improve query performance by optimizing the design of your dimension attributes, cubes, and MDX queries.
Tuning Processing Performance – Processing is the operation that refreshes data in an Analysis Services database. The faster the processing performance, the sooner users can access refreshed data. Analysis Services provides a variety of mechanisms that you can use to influence processing performance, including efficient dimension design, effective aggregations, partitions, and an economical processing strategy (for example, incremental vs. full refresh vs. proactive caching).
Optimizing Special Design Scenarios
– Complex design scenarios require a distinct set of performance tuning techniques to ensure that they are applied successfully, especially if you combine a complex design with large data volumes. Examples of complex design components include special aggregate functions, parent-child hierarchies, complex dimension relationships, and “near real-time” data refreshes.
Tuning Server Resources
–
Analysis Services operates within the constraints of available server resources. Understanding how Analysis Services uses memory, CPU, and disk resources can help you make effective server management decisions that optimize querying and processing performance.
Three appendices provide links to additional resources, information on various partition storage modes, and guidance on using the Aggregation Utility that is a part of SQL Server 2005 Service Pack 2 samples.
Enhancing Query Performance
Querying is the operation where Analysis Services provides data to client applications according to the calculation and data requirements of a MultiDimensional eXpressions (MDX) query. Since query performance directly impacts the user experience, this section describes the most significant opportunities to improve query performance. Following is an overview of the query performance topics that are addressed in this section:
Understanding the querying architecture – The
Analysis Services querying architecture supports three major operations: session management, MDX query execution, and data retrieval. Optimizing query performance involves understanding how these three operations work together to satisfy query requests.
Optimizing the dimension design – A well-tuned dimension design is perhaps one of the most critical success factors of a high-performing Analysis Services solution. Creating attribute relationships and exposing attributes in hierarchies are design choices that influence effective aggregation design, optimized MDX calculation resolution, and efficient dimension data storage and retrieval from disk.
Maximizing the value of aggregations – Aggregations improve query performance by providing precalculated summaries of data. To maximize the value of aggregations, ensure that you have an effective aggregation design that satisfies the needs of your specific workload.
Using partitions to enhance query performance – Partitions provide a mechanism to separate measure group data into physical units that improve query performance, improve processing performance, and facilitate data management. Partitions are naturally queried in parallel; however, there are some design choices and server property optimizations that you can specify to optimize partition operations for your server configuration.
Writing efficient MDX – This section describes techniques for writing efficient MDX statements such as: 1) writing statements that address a narrowly defined calculation space, 2) designing calculations for the greatest re-usage across multiple users, and 3) writing calculations in a straight-forward manner to help the Query Execution Engine select the most efficient execution path.
Understanding the querying architecture
To make the querying experience as fast as possible for end users, the Analysis Services querying architecture provides several components that work together to efficiently retrieve and evaluate data. Figure 1 identifies the three major operations that occur during querying: session management, MDX query execution, and data retrieval as well as the server components that participate in each operation.
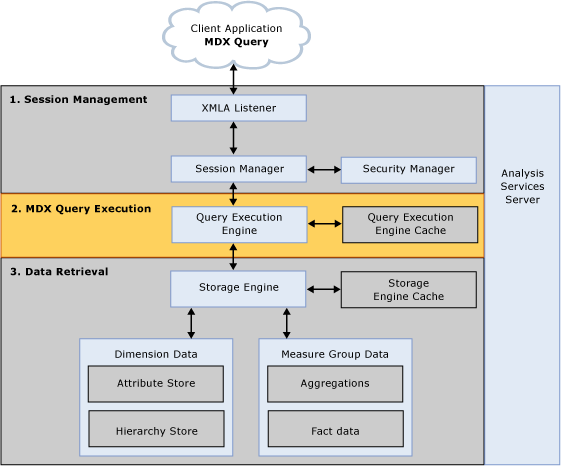
Figure 1 Analysis Services querying architecture
Session management
Client applications communicate with Analysis Services using XML for Analysis (XMLA) over TCP IP or HTTP. Analysis Services provides an XMLA listener component that handles all XMLA communications between Analysis Services and its clients. The Analysis Services Session Manager controls how clients connect to an Analysis Services instance. Users authenticated by Microsoft® Windows and who have rights to Analysis Services can connect to Analysis Services. After a user connects to Analysis Services, the Security Manager determines user permissions based on the combination of Analysis Services roles that apply to the user. Depending on the client application architecture and the security privileges of the connection, the client creates a session when the application starts, and then reuses the session for all of the user’s requests. The session provides the context under which client queries are executed by the Query Execution Engine. A session exists until it is either closed by the client application, or until the server needs to expire it. For more information regarding the longevity of sessions, see Monitoring the timeout of idle sessions in this white paper.
MDX query execution
The primary operation of the Query Execution Engine is to execute MDX queries. This section provides an overview of how the Query Execution Engine executes queries. To learn more details about optimizing MDX, see Writing efficient MDX later in this white paper.
While the actual query execution process is performed in several stages, from a performance perspective, the Query Execution engine must consider two basic requirements: retrieving data and producing the result set.
- Retrieving data—To retrieve the data requested by a query, the Query Execution Engine decomposes each MDX query into data requests. To communicate with the Storage Engine, the Query Execution Engine must translate the data requests into subcube requests that the Storage Engine can understand. A subcube represents a logical unit of querying, caching, and data retrieval. An MDX query may be resolved into one or more subcube requests depending on query granularity and calculation complexity. Note that the word subcube is a generic term. For example, the subcubes that the Query Execution Engine creates during query evaluation are not to be confused with the subcubes that you can create using the MDX CREATE SUBCUBE statement.
-
Producing the result set—To manipulate the data retrieved from the Storage Engine, the Query Execution Engine uses two kinds of execution plans to calculate results: it can bulk calculate an entire subcube, or it can calculate individual cells. In general, the subcube evaluation path is more efficient; however, the Query Execution Engine ultimately selects execution plans based on the complexities of each MDX query. Note that a given query can have multiple execution plans for different parts of the query and/or different calculations involved in the same query. Moreover, different parts of a query may choose either one of these two types of execution plans independently, so there is not a single global decision for the entire query. For example, if a query requests resellers whose year-over-year profitability is greater than 10%, the Query Execution Engine may use one execution plan to calculate each reseller’s year-over-year profitability and another execution plan to only return those resellers whose profitability is greater than 10%.
When you execute an MDX calculation, the Query Execution Engine must often execute the calculation across more cells than you may realize. Consider the example where you have an MDX query that must return the calculated year-to-date sales across the top five regions. While it may seem like you are only returning five cell values, Analysis Services must execute the calculation across additional cells in order to determine the top five regions and also to return their year to date sales. A general MDX optimization technique is to write MDX queries in a way that minimizes the amount of data that the Query Execution Engine must evaluate. To learn more about this MDX optimization technique, see Specifying the calculation space later in this white paper.
As the Query Execution Engine evaluates cells, it uses the Query Execution Engine cache and the Storage Engine Cache to store calculation results. The primary benefits of the cache are to optimize the evaluation of calculations and to support the re-usage of calculation results across users. To optimize cache re-usage, the Query Execution Engine manages three cache scopes that determine the level of cache reusability: global scope, session scope, and query scope. For more information on cache sharing, see Taking advantage of the Query Execution Engine cache in this white paper.
Data retrieval: dimensions
During data retrieval, the Storage Engine must efficiently choose the best mechanism to fulfill the data requests for both dimension data and measure data.
To satisfy requests for dimension data, the Storage Engine extracts data from the dimension attribute and hierarchy stores. As it retrieves the necessary data, the Storage Engine uses dynamic on-demand caching of dimension data rather than keeping all dimension members statically mapped into memory. The Storage Engine simply brings members into memory as they are needed. Dimension data structures may reside on disk, in Analysis Services memory, or in the Windows operating system file cache, depending on memory load of the system.
As the name suggests, the Dimension Attribute Store contains all of the information about dimension attributes. The components of the Dimension Attribute Store are displayed in Figure 2.
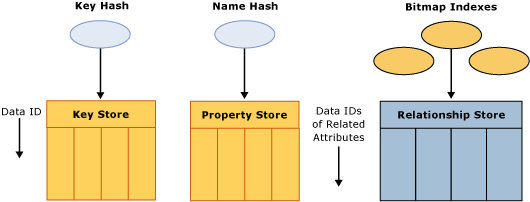
Figure 2 Dimension Attribute Store
As displayed in the diagram, the Dimension Attribute Store contains the following components for each attribute in the dimension:
- Key store—The key store contains the attribute’s key member values as well as an internal unique identifier called a DataID. Analysis Services assigns the DataID to each attribute member and uses the same DataID to refer to that member across all of its stores.
- Property store—The property store contains a variety of attribute properties, including member names and translations. These properties map to specific DataIDs. DataIDs are contiguously allocated starting from zero. Property stores as well as relationship stores (relationship stores are discussed in more detail later) are physically ordered by DataID, in order to ensure fast random access to the contents, without additional index or hash table lookups.
- Hash tables—To facilitate attribute lookups during querying and processing, each attribute has two hash tables which are created during processing and persisted on disk. The Key Hash Table indexes members by their unique keys. A Name Hash Table indexes members by name.
- Relationship store—The Relationship store contains an attribute’s relationships to other attributes. More specifically, the Relationship store stores each source record with DataID references to other attributes. Consider the following example for a product dimension. Product is the key attribute of the dimension with direct attribute relationships to color and size. The data instance of product Sport Helmet, color of Black, and size of Large may be stored in the relationship store as 1001, 25, 5 where 1001 is the DataID for Sport Helmet, 25 is the Data ID for Black, and 5 is the Data ID for Large. Note that if an attribute has no attribute relationships to other attributes, a Relationship Store is not created for that particular attribute. For more information on attribute relationships, see Identifying attribute relationships in this whitepaper.
- Bitmap indexes—To efficiently locate attribute data in the Relationship Store at querying time, the Storage Engine creates bitmap indexes at processing time. For each DataID of a related attribute, the bitmap index states whether or not a page contains at least one record with that DataID. For attributes with a very large number of DataIDs, the bitmap indexes can take some time to process. In most scenarios, the bitmap indexes provide significant querying benefits; however, there is a design scenario where the querying benefit that the bitmap index provides does not outweigh the processing cost of creating the bitmap index in the first place. It is possible to remove the bitmap index creation for a given attribute by setting the AttributeHierarchyOptimizedState property to Not Optimized. For more information on this design scenario, see Reducing attribute overhead in this white paper.
In addition to the attribute store, the Hierarchy Store arranges attributes into navigation paths for end users as displayed in Figure 3.
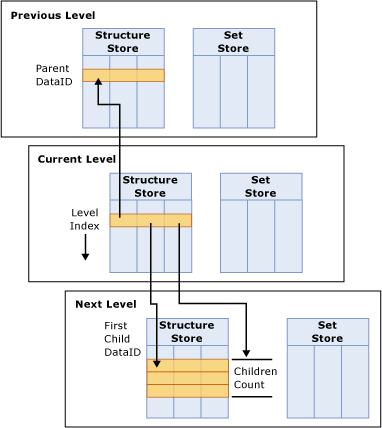
Figure 3 Hierarchy stores
The Hierarchy store consists of the following primary components:
- Set Store—The Set Store uses DataIDs to construct the path of each member, mapped from the first level to the current level. For example, All, Bikes, Mountain Bikes, Mountain Bike 500 may be represented as 1,2,5,6 where 1 is the DataID for All, 2 is the DataID for Bikes, 5 is the DataID for Mountain Bikes, and 6 is the DataID for Mountain Bike 500.
- Structure Store—For each member in a level, the Structure Store contains the DataID of the parent member, the DataID of the first child, and the total children count. The entries in the Structure Store are ordered by each member’s Level index. The Level index of a member is the position of a member in the level as specified by the ordering settings of the dimension. To better understand the Structure Store, consider the following example. If Bikes contains 3 children, the entry for Bikes in the Structure Store would be 1,5,3 where 1 is the DataID for the Bike’s parent, All, 5 is the DataID for Mountain Bikes, and 3 is the number of Bike’s children.
Note that only natural hierarchies are materialized in the hierarchy store and optimized for data retrieval. Unnatural hierarchies are not materialized on disk. For more information on the best practices for designing hierarchies, see Using hierarchies effectively.
Data retrieval: measure group data
For data requests, the Storage Engine retrieves measure group data that is physically stored in partitions. A partition contains two categories of measure group data: fact data and aggregations. To accommodate a variety of data storage architectures, each partition can be assigned a different storage mode that specifies where fact data and aggregations are stored. From a performance perspective, the storage mode that provides the fastest query performance is the Multidimensional Online Analytical Processing (MOLAP) storage mode. In MOLAP, the partition fact data and aggregations are stored in a compressed multidimensional format that Analysis Services manages. For most implementations, MOLAP storage mode should be used; however, if you require additional information about other partition storage modes, see Appendix B. If you are considering a “near real-time” deployment, see Near real-time data refreshes in this white paper.
In MOLAP storage, the data structures for fact data and aggregation data are identical. Each is divided into segments. A segment contains a fixed number of records (typically 64 KB) divided into 256 pages with 256 records in each. Each record stores all of the measures in the partition’s measure group and a set of internal DataIDs that map to the granularity attributes of each dimension. Only records that are present in the relational fact table are stored in the partition, resulting in highly compressed data files.
To efficiently fulfill data requests, the Storage Engine follows an optimized process to satisfy the request by using three general mechanisms, Storage Engine Cache, aggregations, and fact data represented in Figure 4:.

Figure 4 Satisfying data requests
Figure 4 presents a data request for {(Europe, 2005), (Asia, 2005)}. To fulfill this request, the Storage Engine chooses among the following approaches:
- Storage Engine cache—The Storage Engine first attempts to satisfy the data request using the Storage Engine cache. Servicing a data request from the Storage Engine cache provides the best query performance. The Storage Engine cache always resides in memory. For more information on managing the Storage Engine cache, see Memory demands during querying.
- Aggregations—If relevant data is not in the cache, the Storage Engine checks for a precalculated data aggregation. In some scenarios, the aggregation may exactly fit the data request. For example, an exact fit occurs when the query asks for sales by category by year and there is an aggregation that summarizes sales by category by year. While an exact fit is ideal, the Storage Engine can use also data aggregated at a lower level, such as sales aggregated by month and category or sales aggregated by quarter and item. The Storage Engine then summarizes the values on the fly to produce sales by category by year. For more information on how to design aggregations to improve performance, see Maximizing the value of aggregations.
- Fact data—If appropriate aggregations do not exist for a given query, the Storage Engine must retrieve the fact data from the partition. The Storage Engine uses many internal optimizations to effectively retrieve data from disk including enhanced indexing and clustering of related records. For both aggregations and fact data, different portions of data may reside either on disk or in the Windows operating system file cache, depending on memory load of the system.
A key performance tuning technique for optimizing data retrieval is to reduce the amount of data that the Storage Engine needs to scan by using multiple partitions that physically divide your measure group data into distinct data slices. Using multiple partitions can not only enhance querying speed, but they can also provide greater scalability, facilitate data management, and optimize processing performance.
From a querying perspective, the Storage Engine can predetermine the data stored in each MOLAP partition and optimize which MOLAP partitions it scans in parallel. In the example in Figure 4, a partition with 2005 data is displayed in blue and a partition with 2006 data is displayed in orange. The data request displayed in the diagram {(Europe, 2005), (Asia, 2005)} only requires 2005 data. Consequently, the Storage Engine only needs to go to the 2005 partition. To maximize query performance, the Storage Engine uses parallelism, such as scanning partitions in parallel, wherever possible. To locate data in a partition, the Storage Engine queries segments in parallel and uses bitmap indexes to efficiently scan pages to find the desired data.
Partitions are a major component of high-performing cubes. For more information on the broader benefits of partitions, see the following sections in this white paper:
Optimizing the dimension design
A well-tuned dimension design is one of the most critical success factors of a high-performing Analysis Services solution. The two most important techniques that you can use to optimize your dimension design for query performance are:
- Identifying attribute relationships
- Using hierarchies effectively
Identifying attribute relationships
A typical data source of an Analysis Services dimension is a relational data warehouse dimension table. In relational data warehouses, each dimension table typically contains a primary key, attributes, and, in some cases, foreign key relationships to other tables.
Table 1 Column properties of a simple Product dimension table
|
Dimension table column
|
Column type
|
Relationship to primary key
|
Relationship to other columns
|
|
Product Key
|
Primary Key
|
Primary Key
|
—
|
|
Product SKU
|
Attribute
|
1:1
|
—
|
|
Description
|
Attribute
|
1:1
|
—
|
|
Color
|
Attribute
|
Many:1
|
—
|
|
Size
|
Attribute
|
Many:1
|
Many: 1 to Size Range
|
|
Size Range
|
Attribute
|
Many:1
|
|
|
Subcategory
|
Attribute
|
Many:1
|
Many: 1 to Category
|
|
Category
|
Attribute
|
Many:1
|
|
Table 1 displays the design of a simple product dimension table. In this simple example, the product dimension table has one primary key column, the product key. The other columns in the dimension table are attributes that provide descriptive context to the primary key such as product SKU, description, and color. From a relational perspective, all of these attributes either have a many-to-one relationship to the primary key or a one-to-one relationship to the primary key. Some of these attributes also have relationships to other attributes. For example, size has a many-to-one relationship with size range and subcategory has a many-to-one relationship with category.
Just as it is necessary to understand and define the functional dependencies among fields in relational databases, you must also follow the same practices in Analysis Services. Analysis Services must understand the relationships among your attributes in order to correctly aggregate data, effectively store and retrieve data, and create useful aggregations. To help you create these associations among your dimension attributes, Analysis Services provides a feature called attribute relationships. As the name suggests, an attribute relationship describes the relationship between two attributes.
When you initially create a dimension, Analysis Services auto-builds a dimension structure with many-to-one attribute relationships between the primary key attribute and every other dimension attribute as displayed in Figure 5.
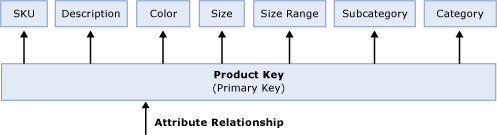
Figure 5 Default attribute relationships
The arrows in Figure 5 represent the attribute relationships between product key and the other attributes in the dimension. While the dimension structure presented in Figure 5 provides a valid representation of the data from the product dimension table, from a performance perspective, it is not an optimized dimension structure since Analysis Services is not aware of the relationships among the attributes.
With this design, whenever you issue a query that includes an attribute from this dimension, data is always summarized from the primary key and then grouped by the attribute. So if you want sales summarized by Subcategory, individual product keys are grouped on the fly by Subcategory. If your query requires sales by Category, individual product keys are once again grouped on the fly by Category. This is somewhat inefficient since Category totals could be derived from Subcategory totals. In addition, with this design, Analysis Services doesn’t know which attribute combinations naturally exist in the dimension and must use the fact data to identify meaningful member combinations. For example, at query time, if a user requests data by Subcategory and Category, Analysis Services must do extra work to determine that the combination of Subcategory: Mountain Bikes and Category: Accessories does not exist.
To optimize this dimension design, you must understand how your attributes are related to each other and then take steps to let Analysis Services know what the relationships are.
To enhance the product dimension, the structure in Figure 6 presents an optimized design that more effectively represents the relationships in the dimension.
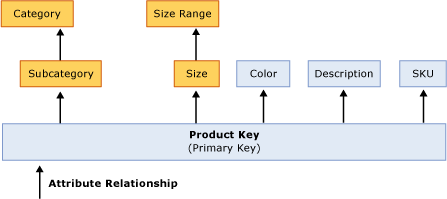
Figure 6 Product dimension with optimized attribute relationships
Note that the dimension design in Figure 6 is different than the design in Figure 5. In Figure 5, the primary key has attribute relationships to every other attribute in the dimension. In Figure 6, two new attribute relationships have been added between Size and Size Range and Subcategory and Category.
The new relationships between Size and Size Range and Subcategory and Category reflect the many-to-one relationships among the attributes in the dimension. Subcategory has a many-to-one relationship with Category. Size has a many-to-one relationship to Size Range. These new relationships tell Analysis Services how the nonprimary key attributes (Size and Size Range, and Subcategory and Category) are related to each other.
Typically many-to-one relationships follow data hierarchies such as the hierarchy of products, subcategories, and categories depicted in Figure 6. While a data hierarchy can commonly suggest many-to-one relationships, do not automatically assume that this is always the case. Whenever you add an attribute relationship between two attributes, it is important to first verify that the attribute data strictly adheres to a many-to-one relationship. As a general rule, you should create an attribute relationship from attribute A to attribute B if and only if the number of distinct (a, b) pairs from A and B is the same (or smaller) than the number of distinct members of A. If you create an attribute relationship and the data violates the many-to-one relationship, you will receive incorrect data results.
Consider the following example. You have a time dimension with a month attribute containing values such as January, February, March and a year attribute containing values such as 2004, 2005, and 2006. If you define an attribute relationship between the month and year attributes, when the dimension is processed, Analysis Services does not know how to distinguish among the months for each year. For example, when it comes across the January member, it does not which year should it roll it up to. The only way to ensure that data is correctly rolled up from month to year is to change the definition of the month attribute to month and year. You make this definition change by changing the KeyColumns property of the attribute to be a combination of month and year.
The KeyColumns property consists of a source column or combination of source columns (known as a collection) that uniquely identifies the members for a given attribute. Once you define attribute relationships among your attributes, the importance of the KeyColumns property is highlighted. For every attribute in your dimension, you must ensure that the KeyColumns property of each attribute uniquely identifies each attribute member. If the KeyColumns property does not uniquely identify each member, duplicates encountered during processing are ignored by default, resulting in incorrect data rollups.
Note that if the attribute relationship has a default Type of Flexible, Analysis Services does not provide any notification that it has encountered duplicate months and incorrectly assigns all of the months to the first year or last year depending on data refresh technique. For more information on the Type property and the impact of your data refresh technique on key duplicate handling, see Optimizing dimension inserts, updates, and deletes in this white paper.
Regardless of your data refresh technique, key duplicates typically result in incorrect data rollups and should be avoided by taking the time to set a unique KeyColumns property. Once you have correctly configured the KeyColumns property to uniquely define an attribute, it is a good practice to change the default error configuration for the dimension so that it no longer ignores duplicates. To do this, set the KeyDuplicate property from IgnoreError to ReportAndContinue or ReportAndStop. With this change, you can be alerted of any situation where the duplicates are detected.
Whenever you define a new attribute relationship, it is critical that you remove any redundant relationships for performance and data correctness. In Figure 6, with the new attribute relationships, the Product Key no longer requires direct relationships to Size Range or Category. As such, these two attribute relationships have been removed. To help you identify redundant attribute relationships, Business Intelligence Development Studio provides a visual warning to alert you about the redundancy; however, it does not require you to eliminate the redundancy. It is a best practice to always manually remove the redundant relationship. Once you remove the redundancy, the warning disappears.
Even though Product Key is no longer directly related to Size Range and Category, it is still indirectly related to these attributes through a chain of attribute relationships. More specifically, Product Key is related to Size Range using the chain of attribute relationships that link Product Key to Size and Size to Size Range. This chain of attribute relationships is also called cascading attribute relationships.
With cascading attribute relationships, Analysis Services can make better performance decisions concerning aggregation design, data storage, data retrieval, and MDX calculations. Beyond performance considerations, attribute relationships are also used to enforce dimension security and to join measure group data to nonprimary key granularity attributes. For example, if you have a measure group that contains sales data by Product Key and forecast data by Subcategory, the forecast measure group will only know how to roll up data from Subcategory to Category if attribute relationships exists between Subcategory and Category.
The core principle behind designing effective attribute relationships is to create the most efficient dimension model that best represents the semantics of your business. While this section provides guidelines and best practices for optimizing your dimension design, to be successful, you must be extremely familiar with your data and the business requirements that the data must support before considering how to tune your design.
Consider the following example. You have a time dimension with an attribute called Day of Week. This attribute contains seven members, one for each day of the week, where the Monday member represents all of the Mondays in your time dimension. Given what you learned from the month / year example, you may think that you should immediately change the KeyColumns property of this attribute to concatenate the day with the calendar date or some other attribute. However, before making this change, you should consider your business requirements. The day-of-week grouping can be valuable in some analysis scenarios such as analyzing retail sales patterns by the day of the week. However, in other applications, the day of the week may only be interesting if it is concatenated with the actual calendar date. In other words, the best design depends on your analysis scenario. So while it is important to follow best practices for modifying dimension properties and creating efficient attribute relationships, ultimately you must ensure that your own business requirements are satisfied. For additional thoughts on various dimension designs for a time dimension, see the blog Time calculations in UDM: Parallel Period.
Using hierarchies effectively
In Analysis Services, attributes can be exposed to users by using two types of hierarchies: attribute hierarchies and user hierarchies. Each of these hierarchies has a different impact on the query performance of your cube.
Attribute hierarchies are the default hierarchies that are created for each dimension attribute to support flexible analysis. For non parent-child hierarchies, each attribute hierarchy consists of two levels: the attribute itself and the All level. The All level is automatically exposed as the top level attribute of each attribute hierarchy.
Note that you can disable the All attribute for a particular attribute hierarchy by using the IsAggregatable property. Disabling the All attribute is generally not advised in most design scenarios. Without the All attribute, your queries must always slice on a specific value from the attribute hierarchy. While you can explicitly control the slice by using the Default Member property, realize that this slice applies across all queries regardless of whether your query specifically references the attribute hierarchy. With this in mind, it is never a good idea to disable the All attribute for multiple attribute hierarchies in the same dimension.
From a performance perspective, attributes that are only exposed in attribute hierarchies are not automatically considered for aggregation. This means that no aggregations include these attributes. Queries involving these attributes are satisfied by summarizing data from the primary key. Without the benefit of aggregations, query performance against these attributes hierarchies can be somewhat slow.
To enhance performance, it is possible to flag an attribute as an aggregation candidate by using the Aggregation Usage property. For more detailed information on this technique, see Suggesting aggregation candidates in this white paper. However, before you modify the Aggregation Usage property, you should consider whether you can take advantage of user hierarchies.
In user hierarchies, attributes are arranged into predefined multilevel navigation trees to facilitate end user analysis. Analysis Services enables you to build two types of user hierarchies: natural and unnatural hierarchies, each with different design and performance characteristics.
- In a natural hierarchy, all attributes participating as levels in the hierarchy have direct or indirect attribute relationships from the bottom of the hierarchy to the top of the hierarchy. In most scenarios, natural hierarchies follow the chain of many-to-one relationships that “naturally” exist in your data. In the product dimension example discussed earlier in Figure 6, you may decide to create a Product Grouping hierarchy that from bottom-to-top consists of Products, Product Subcategories, and Product Categories. In this scenario, from the bottom of the hierarchy to the top of the hierarchy, each attribute is directly related to the attribute in the next level of the hierarchy. In an alternative design scenario, you may have a natural hierarchy that from bottom to top consists of Products and Product Categories. Even though Product Subcategories has been removed, this is still a natural hierarchy since Products is indirectly related to Product Category via cascading attribute relationships.
- In an unnatural hierarchy the hierarchy consists of at least two consecutive levels that have no attribute relationships. Typically these hierarchies are used to create drill-down paths of commonly viewed attributes that do not follow any natural hierarchy. For example, users may want to view a hierarchy of Size Range and Category or vice versa.
From a performance perspective, natural hierarchies behave very differently than unnatural hierarchies. In natural hierarchies, the hierarchy tree is materialized on disk in hierarchy stores. In addition, all attributes participating in natural hierarchies are automatically considered to be aggregation candidates. This is a very important characteristic of natural hierarchies, important enough that you should consider creating natural hierarchies wherever possible. For more information on aggregation candidates, see Suggesting aggregation candidates.
Unnatural hierarchies are not materialized on disk and the attributes participating in unnatural hierarchies are not automatically considered as aggregation candidates. Rather, they simply provide users with easy-to-use drill-down paths for commonly viewed attributes that do not have natural relationships. By assembling these attributes into hierarchies, you can also use a variety of MDX navigation functions to easily perform calculations like percent of parent. An alternative to using unnatural hierarchies is to cross-join the data by using MDX at query time. The performance of the unnatural hierarchies vs. cross-joins at query time is relatively similar. Unnatural hierarchies simply provide the added benefit of reusability and central management.
To take advantage of natural hierarchies, you must make sure that you have correctly set up cascading attribute relationships for all attributes participating in the hierarchy. Since creating attribute relationships and creating hierarchies are two separate operations, it is not uncommon to inadvertently miss an attribute relationship at some point in the hierarchy. If a relationship is missing, Analysis Services classifies the hierarchy as an unnatural hierarchy, even if you intended it be a natural hierarchy.
To verify the type of hierarchy that you have created, Business Intelligence Development Studio issues a warning icon  whenever you create a user hierarchy that is missing one or more attribute relationships. The purpose of the warning icon is to help identify situations where you have intended to create a natural hierarchy but have inadvertently missed attribute relationships. Once you create the appropriate attribute relationships for the hierarchy in question, the warning icon disappears. If you are intentionally creating an unnatural hierarchy, the hierarchy continues to display the warning icon to indicate the missing relationships. In this case, simply ignore the warning icon.
whenever you create a user hierarchy that is missing one or more attribute relationships. The purpose of the warning icon is to help identify situations where you have intended to create a natural hierarchy but have inadvertently missed attribute relationships. Once you create the appropriate attribute relationships for the hierarchy in question, the warning icon disappears. If you are intentionally creating an unnatural hierarchy, the hierarchy continues to display the warning icon to indicate the missing relationships. In this case, simply ignore the warning icon.
In addition, while this is not a performance issue, be mindful of how your attribute hierarchies, natural hierarchies, and unnatural hierarchies are displayed to end users in your front end tool. For example, if you have a series of geography attributes that are generally queried by using a natural hierarchy of Country/Region, State/Province, and City, you may consider hiding the individual attribute hierarchies for each of these attributes in order to prevent redundancy in the user experience. To hide the attribute hierarchies, use the AttributeHierarchyVisible property.
Maximizing the value of aggregations
An aggregation is a precalculated summary of data that Analysis Services uses to enhance query performance. More specifically, an aggregation summarizes measures by a combination of dimension attributes.
Designing aggregations is the process of selecting the most effective aggregations for your querying workload. As you design aggregations, you must consider the querying benefits that aggregations provide compared with the time it takes to create and refresh the aggregations. On average, having more aggregations helps query performance but increases the processing time involved with building aggregations.
While aggregations are physically designed per measure group partition, the optimization techniques for maximizing aggregation design apply whether you have one or many partitions. In this section, unless otherwise stated, aggregations are discussed in the fundamental context of a cube with a single measure group and single partition. For more information on how you can improve query performance using multiple partitions, see Using partitions to enhance query performance.
How aggregations help
While pre-aggregating data to improve query performance sounds reasonable, how do aggregations actually help Analysis Services satisfy queries more efficiently? The answer is simple. Aggregations reduce the number of records that the Storage Engine needs to scan from disk in order to satisfy a query. To gain some perspective on how this works, first consider how the Storage Engine satisfies a query against a cube with no aggregations.
While you may think that the number of measures and fact table records are the most important factors in aggregating data, dimensions actually play the most critical role in data aggregation, determining how data is summarized in user queries. To help you visualize this, Figure 7 displays three dimensions of a simple sales cube.

Figure 7 Product, Customer, and Order Date dimensions
Each dimension has four attributes. At the grain of the cube, there are 200 individual products, 5,000 individual customers, and 1,095 order dates. The maximum potential number of detailed values in this cube is the Cartesian product of these numbers: 200 * 5000 * 1095 or 109,500,000 theoretical combinations. This theoretical value is only possible if every customer buys every product on every day of every year, which is unlikely. In reality, the data distribution is likely a couple of orders of magnitude lower than the theoretical value. For this scenario, assume that the example cube has 1,095,000 combinations at the grain, a factor of 100 lower than the theoretical value.
Querying the cube at the grain is uncommon, given that such a large result set (1,095,000 cells) is probably not useful for end users. For any query that is not at the cube grain, the Storage Engine must perform an on-the-fly summarization of the detailed cells by the other dimension attributes, which can be costly to query performance. To optimize this summarization, Analysis Services uses aggregations to precalculate and store summaries of data during cube processing. With the aggregations readily available at query time, query performance can be improved greatly.
Continuing with the same cube example, if the cube contains an aggregation of sales by the month and product subcategory attributes, a query that requires sales by month by product subcategory can be directly satisfied by the aggregation without going to the fact data. The maximum number of cells in this aggregation is 720 (20 product subcategory members * 36 months, excluding the All attribute). While the actual number cells in the aggregation is again dependent on the data distribution, the maximum number of cells, 720, is considerably more efficient than summarizing values from 1,095,000 cells.
In addition, the benefit of the aggregation applies beyond those queries that directly match the aggregation. Whenever a query request is issued, the Storage Engine attempts to use any aggregation that can help satisfy the query request, including aggregations that are at a finer level of detail. For these queries, the Storage Engine simply summarizes the cells in the aggregation to produce the desired result set. For example, if you request sales data summarized by month and product category, the Storage Engine can quickly summarize the cells in the month and product subcategory aggregation to satisfy the query, rather than re-summarizing data from the lowest level of detail. To realize this benefit, however, requires that you have properly designed your dimensions with attribute relationships and natural hierarchies so that Analysis Services understands how attributes are related to each other. For more information on dimension design, see Optimizing the dimension design.
How the Storage Engine uses aggregations
To gain some insight into how the Storage Engine uses aggregations, you can use SQL Server Profiler to view how and when aggregations are used to satisfy queries. Within SQL Server Profiler, there are several events that describe how a query is fulfilled. The event that specifically pertains to aggregation hits is the Get Data From Aggregation event. Figure 8 displays a sample query and result set from an example cube.
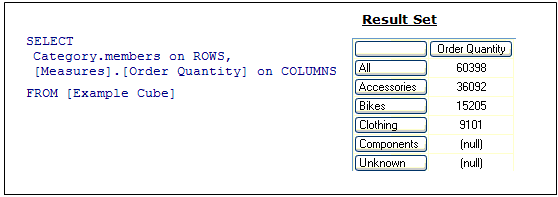
Figure 8 Sample query and result set
For the query displayed in Figure 8, you can use SQL Server Profiler to compare how the query is resolved in the following two scenarios:
- Scenario 1—Querying against a cube where an aggregation satisfies the query request.
- Scenario 2—Querying against a cube where no aggregation satisfies the query request.
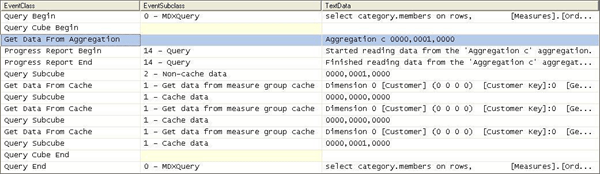
Figure 9 Scenario 1: SQL Server Profiler trace for cube with an aggregation hit
Figure 9 displays a SQL Server Profiler trace of the query’s resolution against a cube with aggregations. In the SQL Server Profiler trace, you can see the operations that the Storage Engine performs to produce the result set.
To satisfy the query, the following operations are performed:
-
After the query is submitted, the Storage Engine gets data from Aggregation C 0000, 0001, 0000 as indicated by the Get Data From Aggregation event.
Aggregation C is the name of the aggregation. Analysis Services assigns the aggregation with a unique name in hexadecimal format. Note that aggregations that have been migrated from earlier versions of Analysis Services use a different naming convention.
- In addition to the aggregation name, Aggregation C, Figure 9 displays a vector, 000, 0001, 0000 , that describes the content of the aggregation. More information on what this vector actually means is described in How to interpret aggregations.
- The aggregation data is loaded into the Storage Engine measure group cache.
- Once in the measure group cache, the Query Execution Engine retrieves the data from the cache and returns the result set to the client.

Figure 10 Scenario 2: SQL Server Profiler trace for cube with no aggregation hit
Figure 10 displays a SQL Server Profiler trace for the same query against the same cube but this time, the cube has no aggregations that can satisfy the query request.
To satisfy the query, the following operations are performed:
- After the query is submitted, rather than retrieving data from an aggregation, the Storage Engine goes to the detail data in the partition.
- From this point, the process is the same. The data is loaded into the Storage Engine measure group cache.
- Once in the measure group cache, the Query Execution Engine retrieves the data from the cache and returns the result set to the client.
To summarize these two scenarios, when SQL Server Profiler displays Get Data From Aggregation, this indicates an aggregation hit. With an aggregation hit, the Storage Engine can retrieve part or all of the data answer from the aggregation and does not need to go to the data detail. Other than fast response times, aggregation hits are a primary indication of a successful aggregation design.
To help you achieve an effective aggregation design, Analysis Services provides tools and techniques to help you create aggregations for your query workload. For more information on these tools and techniques, see Which aggregations are built in this white paper. Once you have created and deployed your aggregations, SQL Server Profiler provides excellent insight to help you monitor aggregation usage over the lifecycle of the application.
Why not create every possible aggregation?
Since aggregations can significantly improve query performance, you may wonder why not create every possible aggregation? Before answering this question, first consider what creating every possible aggregation actually means in theoretical terms.
Note that the goal of this theoretical discussion is to help you understand how aggregations work in an attribute-based architecture. It is not meant to be a discussion of how Analysis Services actually determines which aggregations are built. For more information on this topic, see Which aggregations are built in this white paper.
Generally speaking, an aggregation summarizes measures by a combination of attributes. From an aggregation perspective, for each attribute, there are two levels of detail: the attribute itself and the All attribute. Figure 11 displays the levels of detail for each attribute in the product dimension.

Figure 11 Attribute levels for the product dimension
With four attributes and two levels of detail (All and attribute), the total possible combination for the product dimension is 2*2*2*2 or 2^4 = 16 vectors or potential aggregations.

Figure 12 (3) dimensions with (4) attributes per dimension
If you apply this logic across all attributes displayed in Figure 12, the total number of possible aggregations can be represented as follows:
Total Number of Aggregations
2 (product key) *2 (color) *2 (product subcategory) * 2 (product category)*
2 (customer key) *2 (gender) *2 (city) *2 (state/province) *
2 (order date key) * 2 (month) * 2 (quarter)* 2 (year)
= 2^12
= 4096
Based on this example, the total potential aggregations of any cube can be expressed as 2^ (total number of attributes). While a cube with twelve attributes produces 4,096 theoretical aggregations, a large scale cube may have hundreds of attributes and consequently an exponential increase in the number of aggregations. A cube with 100 attributes, for example, would have 1.26765E+30 theoretical aggregations!
The good news is that this is just a theoretical discussion. Analysis Services only considers a small percentage of these theoretical aggregations, and eventually creates an even smaller subset of aggregations. As a general rule, an effective Analysis Services aggregation design typically contains tens or hundreds of aggregations, not thousands.
With that in mind, the theoretical discussion reminds us that as you add additional attributes to your cube, you are potentially increasing the number of aggregations that Analysis Services must consider. Furthermore, since aggregations are created at the time of cube processing, too many aggregations can negatively impact processing performance or require excessive disk space to store. As a result, ensure that your aggregation design supports the required data refresh timeline.
How to interpret aggregations
When Analysis Services creates an aggregation, each dimension is named by a vector, indicating whether the attribute points to the attribute or to the All level. The Attribute level is represented by 1 and the All level is represented by 0. For example, consider the following examples of aggregation vectors for the product dimension:
- Aggregation By ProductKey Attribute
= [Product Key]:1 [Color]:0 [Subcategory]:0 [Category]:0 or 1000
- Aggregation By Category Attribute
= [Product Key]:0 [Color]:0 [Subcategory]:0 [Category]:1 or 0001
- Aggregation By ProductKey.All
and Color.All and Subcategory.All and Category.All = [Product Key]:0 [Color]:0 [Subcategory]:0 [Category]:0 or 0000
To identify each aggregation, Analysis Services combines the dimension vectors into one long vector path, also called a subcube, with each dimension vector separated by commas.
The order of the dimensions in the vector is determined by the order of the dimensions in the cube. To find the order of dimensions in the cube, use one of the following two techniques. With the cube opened in SQL Server Business Intelligence Development Studio, you can review the order of dimensions in a cube on the Cube Structure tab. The order of dimensions in the cube is displayed in the Dimensions pane, on both the Hierarchies tab and the Attributes tab. As an alternative, you can review the order of dimensions listed in the cube XML file.
The order of attributes in the vector for each dimension is determined by the order of attributes in the dimension. You can identify the order of attributes in each dimension by reviewing the dimension XML file.
For example, the following subcube definition (0000, 0001, 0001) describes an aggregation for:
Product – All, All, All, All
Customer – All, All, All, State/Province
Order Date – All, All, All, Year
Understanding how to read these vectors is helpful when you review aggregation hits in SQL Server Profiler. In SQL Server Profiler, you can view how the vector maps to specific dimension attributes by enabling the Query Subcube Verbose event.
Which aggregations are built
To decide which aggregations are considered and created, Analysis Services provides an aggregation design algorithm that uses a cost/benefit analysis to assess the relative value of each aggregation candidate.
- Aggregation Cost—The cost of an aggregation is primarily influenced by the aggregation size. To calculate the size, Analysis Services gathers statistics including source record counts and member counts, as well as design metadata including the number of dimensions, measures, and attributes. Once the aggregation cost is calculated, Analysis Services performs a series of tests to evaluate the cost against absolute cost thresholds and to evaluate the cost compared to other aggregations.
- Aggregation Benefit—The benefit of the aggregation depends on how well it reduces the amount of data that must be scanned during querying. For example, if you have 1,000,000 data values that are summarized into an aggregation of fifty values, this aggregation greatly benefits query performance. Remember that Analysis Services can satisfy queries by using an aggregation that matches the query subcube exactly, or by summarizing data from an aggregation at a lower level (a more detailed level). As Analysis Services determines which aggregations should be built, the algorithm needs to understand how attributes are related to each other so it can detect which aggregations provide the greatest coverage and which aggregations are potentially redundant and unnecessary.
To help you build aggregations, Analysis Services exposes the algorithm using two tools: the Aggregation Design Wizard and the Usage-Based Optimization Wizard.
- The Aggregation Design Wizard designs aggregations based on your cube design and data distribution. Behind the scenes, it selects aggregations using a cost/benefit algorithm that accepts inputs about the design and data distribution of the cube. The Aggregation Design Wizard can be accessed in either Business Intelligence Development Studio or SQL Server Management Studio.
- The Usage-Based Optimization
Wizard designs aggregations based on query usage patterns. The Usage-Based Optimization Wizard uses the same cost/benefit algorithm as the Aggregation Design Wizard except that it provides additional weighting to those aggregation candidates that are present in the Analysis Services query log. The Usage-Based Optimization Wizard can be accessed in either Business Intelligence Development Studio (BIDS) or SQL Server Management Studio. To use the Usage-Based Optimization Wizard, you must capture end-user queries and store the queries in a query log. To set up and configure the query log for an instance of Analysis Services, you can access a variety of configuration settings in SQL Server Management Studio to control the sampling frequency of queries and the location of the query log.
In those special scenarios when you require finer grained control over aggregation design, SQL Server Service Pack 2 samples includes an advanced Aggregation utility. Using this advanced tool, you can manually create aggregations without using the aggregation design algorithm. For more information on the Aggregation utility, see Appendix C.
How to impact aggregation design
To help Analysis Services successfully apply the aggregation design algorithm, you can perform the following optimization techniques to influence and enhance the aggregation design. (The sections that follow describe each of these techniques in more detail).
Suggesting aggregation candidates – When Analysis Services designs aggregations, the aggregation design algorithm does not automatically consider every attribute for aggregation. Consequently, in your cube design, verify the attributes that are considered for aggregation and determine whether you need to suggest additional aggregation candidates.
Specifying statistics about cube data
– To make intelligent assessments of aggregation costs, the design algorithm analyzes statistics about the cube for each aggregation candidate. Examples of this metadata include member counts and fact table counts. Ensuring that your metadata is up-to-date can improve the effectiveness of your aggregation design.
Adopting an aggregation design strategy – To help you design the most effective aggregations for your implementation, it is useful to adopt an aggregation design strategy that leverages the strengths of each of the aggregation design methods at various stages of your development lifecycle.
Suggesting aggregation candidates
When Analysis Services designs aggregations, the aggregation design algorithm does not automatically consider every attribute for aggregation. Remember the discussion of the potential number of aggregations in a cube? If Analysis Services were to consider every attribute for aggregation, it would take too long to design the aggregations, let alone populate them with data. To streamline this process, Analysis Services uses the Aggregation Usage property to determine which attributes it should automatically consider for aggregation. For every measure group, verify the attributes that are automatically considered for aggregation and then determine whether you need to suggest additional aggregation candidates.
The aggregation usage rules
An aggregation candidate is an attribute that Analysis Services considers for potential aggregation. To determine whether or not a specific attribute is an aggregation candidate, the Storage Engine relies on the value of the Aggregation Usage property. The Aggregation Usage property is assigned a per-cube attribute, so it globally applies across all measure groups and partitions in the cube. For each attribute in a cube, the Aggregation Usage property can have one of four potential values: Full, None, Unrestricted, and Default.
- Full: Every aggregation for the cube must include this attribute or a related attribute that is lower in the attribute chain. For example, you have a product dimension with the following chain of related attributes: Product, Product Subcategory, and Product Category. If you specify the Aggregation Usage for Product Category to be Full, Analysis Services may create an aggregation that includes Product Subcategory as opposed to Product Category, given that Product Subcategory is related to Category and can be used to derive Category totals.
- None—No aggregation for the cube may include this attribute.
- Unrestricted—No restrictions are placed on the aggregation designer; however, the attribute must still be evaluated to determine whether it is a valuable aggregation candidate.
- Default—The designer applies a default rule based on the type of attribute and dimension. As you may guess, this is the default value of the Aggregation Usage property.
The default rule is highly conservative about which attributes are considered for aggregation. Therefore, it is extremely important that you understand how the default rule works. The default rule is broken down into four constraints:
-
Default Constraint 1—Unrestricted for the Granularity and All Attributes – For the dimension attribute that is the measure group granularity attribute and the All attribute, apply Unrestricted. The granularity attribute is the same as the dimension’s key attribute as long as the measure group joins to a dimension using the primary key attribute.
To help you visualize how Default Constraint 1 is applied, Figure 13 displays a product dimension with six attributes. Each attribute is displayed as an attribute hierarchy. In addition, three user hierarchies are included in the dimension. Within the user hierarchies, there are two natural hierarchies displayed in blue and one unnatural hierarchy displayed in grey. In addition to the All attribute (not pictured in the diagram), the attribute in yellow, Product Key, is the only aggregation candidate that is considered after the first constraint is applied. Product Key is the granularity attribute for the measure group.
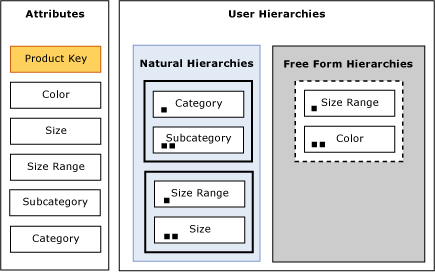
Figure 13 Product dimension aggregation candidates after applying Default Constraint 1
- Default Constraint 2—None for Special Dimension Types – For all attributes (except All) in many-to-many, nonmaterialized reference dimensions, and data mining dimensions, use None. The product dimension in Figure 13 is a standard dimension. Therefore it is not affected by constraint 2. For more information on many-to-many and reference dimensions, see Complex dimension relationships.
-
Default Constraint 3—Unrestricted for Natural Hierarchies – For all user hierarchies, apply a special scanning process to identify the attributes in natural hierarchies. As you recall, a natural
hierarchy is a user hierarchy where all attributes participating in the hierarchy contain attribute relationships at every level of the hierarchy.
To identify the natural hierarchies, Analysis Services scans each user hierarchy starting at the top level and then moves down through the hierarchy to the bottom level. For each level, it checks whether the attribute of the current level is linked to the attribute of the next level via a direct or indirect attribute relationship, for every attribute that pass the natural hierarchy test, apply Unrestricted, except for nonaggregatable attributes, which are set to Full.
- Default Constraint 4—None For Everything Else. For all other dimension attributes, apply None. In this example, the color attribute falls into this bucket since it is only exposed as an attribute hierarchy.
Figure 14 displays what the Product dimension looks like after all constraints in the default rule have been applied. The attributes in yellow highlight the aggregation candidates.
- As a result of Default Constraint 1, the Product Key and All attributes have been identified as candidates.
- As a result of Default Constraint 3, the Size, Size Range, Subcategory, and Category attributes have also been identified as candidates.
- After Default Constraint 4 is applied, Color is still not considered for any aggregation.
Figure 14 Product dimension aggregation candidates after all application of all default constraints
While the diagrams are helpful to visualize what happens after the each constraint is applied, you can view the specific aggregation candidates for your own implementation when you use the Aggregation Design Wizard to design aggregations.
Figure 15 displays the Specify Object Counts page of the Aggregation Design Wizard. On this Wizard page, you can view the aggregation candidates for the Product dimension displayed in Figure 14. The bold attributes in the Product Dimension are the aggregation candidates for this dimension. The Color attribute is not bold because it is not an aggregation candidate. This Specify Object Counts page is discussed again in Specifying statistics about cube metadata, which describes how you can update statistics to improve aggregation design.
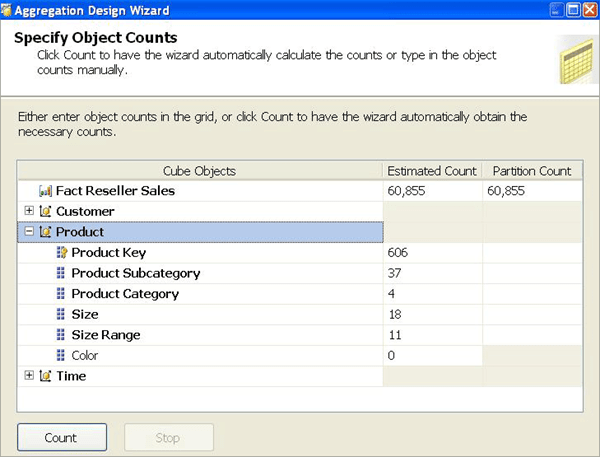
Figure 15 Aggregation candidates in the Aggregation Design Wizard
Influencing aggregation candidates
In light of the behavior of the Aggregation Usage property, following are some guidelines that you can adopt to influence the aggregation candidates for your implementation. Note that by making these modifications, you are influencing the aggregation candidates, not guaranteeing that a specific aggregation is going to be created. The aggregation must still be evaluated for its relative cost and benefit before it is created. The guidelines have been organized into three design scenarios:
Specifying statistics about cube data
Once the aggregation design algorithm has identified the aggregation candidates, it performs a cost/benefit analysis of each aggregation. In order to make intelligent assessments of aggregation costs, the design algorithm analyzes statistics about the cube for each aggregation candidate. Examples of this metadata include member counts and fact table record counts. Ensuring that your metadata is up-to-date can improve the effectiveness of your aggregation design.
You can define the fact table source record count in the EstimatedRows property of each measure group, and you can define attribute member count in the EstimatedCount property of each attribute.
You can modify these counts in the Specify Counts page of the Aggregation Design Wizard as displayed in Figure 16.

Figure 16 Specify object counts in the Aggregation Design Wizard
If the count is NULL (i.e., you did not define it during design), clicking the Count button populates the counts for each aggregation candidate as well as the fact table size. If the count is already populated, clicking the Count button does not update the counts. Rather you must manually change the counts either in the dialog box or programmatically. This is significant when you design aggregations on a small data set and then move the cube to a production database. Unless you update the counts, any aggregation design is built by using the statistics from the development data set.
In addition, when you use multiple partitions to physically divide your data, it is important that the partition counts accurately reflect the data in the partition and not the data across the measure group. So if you create one partition per year, the partition count for the year attribute should be 1. Any blank counts in the Partition Count column use the Estimated Count values, which apply to the entire fact table.
Using these statistics, Analysis Services compares the cost of each aggregation to predefined cost thresholds to determine whether or not an aggregation is too expensive to build. If the cost is too high, it is immediately discarded. One of the most important cost thresholds is known as the one-third rule. Analysis Services never builds an aggregation that is greater than one third of the size of the fact table. In practical terms, the one-third rule typically prevents the building of aggregations that include one or more large attributes.
As the number of dimension members increases at deeper levels in a cube, it becomes less likely that an aggregation will contain these lower levels because of the one-third rule. The aggregations excluded by the one-third rule are those that would be almost as large as the fact level itself and almost as expensive for Analysis Services to use for query resolution as the fact level. As a result, they add little or no value.
When you have dimensions with a large number of members, this threshold can easily be exceeded at or near the leaf level. For example, you have a measure group with the following design:
- Customer dimension with 5,000,000 individual customers organized into 50,000 sales districts and 5,000 sales territories
- Product dimension with 10,000 products organized into 1,000 subcategories and 30 categories
- Time dimension with 1,095 days organized into 36 months and 3 years
- Sales fact table with 12,000,000 sales records
If you model this measure group using a single partition, Analysis Services does not consider any aggregation that exceeds 4,000,000 records (one third of the size of the partition). For example, it does not consider any aggregation that includes the individual customer, given that the customer attribute itself exceeds the one-third rule. In addition, it does not consider an aggregation of sales territory, category, and month since the total number of records of that aggregation could potentially be 5.4 million records consisting of 5,000 sales territories, 30 categories, and 36 months.
If you model this measure group using multiple partitions, you can impact the aggregation design by breaking down the measure group into smaller physical components and adjusting the statistics for each partition.
For example, if you break down the measure group into 36 monthly partitions, you may have the following data statistics per partition:
- Customer dimension has 600,000 individual customers organized into 10,000 sales districts and 3,000 sales territories
- Product dimension with 7,500 products organized into 700 subcategories and 25 categories
- Time dimension with 1 month and 1 year
- Sales fact table with 1,000,000 sales records
With the data broken down into smaller components, Analysis Services can now identify additional useful aggregations. For example, the aggregation for sales territory, category, and month is now a good candidate with (3000 sales territories *25 categories *1 month) or 75,000 records which is less than one third of the partition size of 1,000,000 records. While creating multiple partitions is helpful, it is also critical that you update the member count and partition count for the partition as displayed in Figure 16. If you do not update the statistics, Analysis Services will not know that the partition contains a reduced data set. Note that this example has been provided to illustrate how you can use multiple partitions to impact aggregation design. For practical partition sizing guidelines, including the recommended number of records per partition, see Designing partitions in this white paper.
Note that you can examine metadata stored on, and retrieve support and monitoring information from, an Analysis Services instance by using XML for Analysis (XMLA) schema rowsets. Using this technique, you can access information regarding partition record counts and aggregation size on disk to help you get a better sense of the footprint of Analysis Services cubes.
Adopting an aggregation design strategy
The goal of an aggregation design strategy is to help you design and maintain aggregations throughout your implementation lifecycle. From an aggregation perspective, the cube lifecycle can be broken down into two general stages: initial aggregation design and ongoing tuning based on query patterns.
Initial Aggregation Design
The most effective aggregation designs are those that are customized for the querying patterns of your user base. Unfortunately, when you initially deploy a cube, you probably will not have query usage data available. As such, it is not possible to use the Usage-Based Optimization Wizard. However, because Analysis Services generally resolves user queries faster with some aggregations than with none, you should initially design a limited number of aggregations by using the Aggregation Design Wizard. The number of initial aggregations that you should design depends on the complexity and size of the cube (the fact size).
- Small cubes—With a small cube, an effective aggregation strategy is to initially design aggregations using the Aggregation Design Wizard to achieve a 20 to 30 percent increase in performance. Note that if the design has too many attributes to consider for aggregation, there is a chance that the Aggregation Design Wizard will stop before reaching the designed percent performance improvement and the user interface may not visibly show any percent performance increase. In this scenario, the large number of attributes has resulted in many possible aggregations, and the number of aggregations that have actually been created are a very small percentage of the total possible aggregations.
- Large and complex cubes—With a large and complex cube, it takes Analysis Services a long time just to design a small percentage of the possible aggregations. Recall that the number of theoretical aggregations in a cube can be expressed as 2^ (total number of Unrestricted attributes). A complex cube with five dimensions that each contain eight attributes has 2^40 or 1.1 trillion aggregation candidates (given that every attribute is an aggregation candidate). With this number, if you assume that the Aggregation Design Wizard can examine 1000 aggregations per second (which is a very generous estimate), it will take the Aggregation Design Wizard approximately 35 years to consider a trillion possible aggregations. Furthermore, a large number of aggregations takes a long time to calculate and consumes a large amount of disk space. While this is a theoretical example, an effective approach with real world cubes that are large and complex is to initially design aggregations to achieve a small performance increase (less than 10 percent and possibly even 1 or 2 percent with very complex cubes) and then allow the Aggregation Design Wizard to run for no more than 15 minutes.
- Medium complexity cubes—With a medium-complexity cube, design aggregations to achieve a 10 to 20 percent increase in performance. Then, allow the wizard to run for no more than 15 minutes. While it is difficult to define what constitutes a high-complexity cube versus a medium-complexity cube, consider this general guideline: a high-complexity cube is a cube contains more than ten Unrestricted attributes in any given dimension.
Before you create initial aggregations with the Aggregation Design Wizard, you should evaluate the application Aggregation Usage property and modify its value as necessary to minimize aggregations that are rarely used and to maximize the probability of useful aggregations. Using Aggregation Usage is equivalent to providing the aggregation algorithm with “hints” about which attributes are frequently and infrequently queried. For specific guidelines on modifying the Aggregation Usage property, see Influencing aggregation candidates.
After you design aggregations for a given partition, it is a good practice to evaluate the size of the aggregation files. The total size of all aggregation files for a given partition should be approximately one to two times the size of the source fact table. If the aggregations are greater than two times the size of the fact table, you are likely spending a long time processing your cube to build relatively large aggregation files. During querying, you can potentially experience performance issues when large aggregation files cannot be effectively loaded into memory due to lack of system resources. If you experience these issues, it is good practice to consider reducing the number of aggregation candidates.
Ongoing tuning based on query patterns
After users have queried the cube for a sufficient period of time to gather useful query pattern data in the query log (perhaps a week or two), use the Usage-Based Optimization Wizard to perform a usage-based analysis for designing additional aggregations that would be useful based on actual user query patterns. You can then process the partition to create the new set of aggregations. As usage patterns change, use the Usage-Based Optimization Wizard to update additional aggregations.
Remember that to use the Usage-Based Optimization Wizard, you must capture end-user queries and store the queries in a query log. Logging queries requires a certain amount of overhead so it is generally recommended that you turn off logging and then turn it back on periodically when you need to tune aggregations based on query patterns.
As an alternative to using the Usage-Based Optimization Wizard, if you require finer grained control over aggregation design, SQL Server Service Pack 2 samples includes an advanced Aggregation Utility that allows you to create specific aggregations from the query log without using the aggregation design algorithm. For more information on the Aggregation Utility, see Appendix C.
Using partitions to enhance query performance
Partitions separate measure group data into physical units. Effective use of partitions can enhance query performance, improve processing performance, and facilitate data management. This section specifically addresses how you can use partitions to improve query performance. The Using partitions to enhance processing performance section discusses the processing and data management benefits of partitions.
How partitions are used in querying
When you query a cube, the Storage Engine attempts to retrieve data from the Storage Engine cache. If no data is available in the cache, it attempts to retrieve data from an aggregation. If no aggregation is present, it must go to the fact data. If you have one partition, Analysis Services must scan though all of the fact data in the partition to find the data that you are interested in. While the Storage Engine can query the partition in parallel and use bitmap indexes to speed up data retrieval, with just one partition, performance is not going to be optimal.
As an alternative, you can use multiple partitions to break up your measure group into separate physical components. Each partition can be queried separately and the Storage Engine can query only the partition(s) that contain the relevant data.
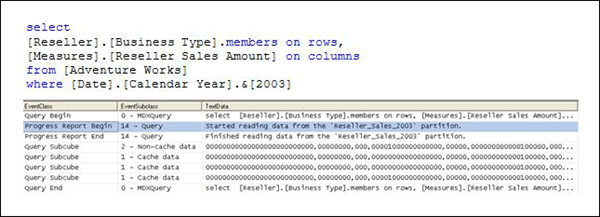
Figure 17 Intelligent querying by partitions
Figure 17 displays a query requesting Reseller Sales Amount by Business Type from a cube called Adventure Works as well as the SQL Server Profiler trace that describes how the query was satisfied. The Reseller Sales measure group of the Adventure Works cube contains four partitions: one for each year. Because the query slices on 2003, the Storage Engine can go directly to the 2003 Reseller Sales partition and does not have to scan data from other partitions. The SQL Server Profiler trace for this query demonstrates how the query needs to read data only from the 2003 Reseller Sales partition.
Designing partitions
If you have some idea how users query the data, you can partition data in a manner that matches common queries. This may be somewhat difficult if user queries do not follow common patterns. A very common choice for partitions is to select an element of time such as day, month, quarter, year or some combination of time elements. Many queries contain a time element, so partitioning by time often benefits query performance.
When you set up your partitions, you must bind each partition to a source table, view, or source query that contains the subset of data for that partition. For MOLAP partitions, during processing Analysis Services internally identifies the slice of data that is contained in each partition by using the Min and Max DataIDs of each attribute to calculate the range of data that is contained in the partition. The data range for each attribute is then combined to create the slice definition for the partition. The slice definition is persisted as a subcube. Knowing this information, the Storage Engine can optimize which partitions it scans during querying by only choosing those partitions that are relevant to the query. For ROLAP and proactive caching partitions, you must manually identify the slice in the properties of the partition.
As you design partitions, use the following guidelines for creating and managing partitions:
- When you decide how to break down your data into partitions, you are generally weighing out partition size vs. number of partitions. Partition size is a function of the number of records in the partition as well as the size of the aggregation files for that partition. Even though the segments in a partition are queried in parallel, if the aggregation files for a partition cannot be effectively managed in memory, you can see significant performance issues during querying.
- In general. the number of records per partition should not exceed 20 million. In addition, the size of a partition should not exceed 250 MB. If the partition exceeds either one of these thresholds, consider breaking the partition into smaller components to reduce the amount of time spent scanning the partition. While having multiple partitions is generally beneficial, having too many partitions, e.g., greater than a few hundred, can also affect performance negatively.
- If you have several partitions that are less than 50 MB or 2 million records per partition, consider consolidating them into one partition. In addition, it is generally not a good practice to create a partition that has less than 4,096 records. In this scenario, given that the record count is so small, the Storage Engine does not create aggregations or indexes for the partition and therefore does not set the auto-slice. Note that this record count threshold is controlled by the IndexBuildThreshold property in the msmdsrv.ini file. Falling below this threshold is generally not an issue in production environments since partition data sets are typically much larger than 4,096 records.
- When you define your partitions, remember that they do not have to contain uniform datasets. For example, for a given measure group, you may have three yearly partitions, 11 monthly partitions, three weekly partitions, and 1–7 daily partitions. The value of using heterogeneous partitions with different levels of detail is that you can more easily manage the loading of new data without disturbing existing partitions. In addition, you can design aggregations for groups of partitions that share the same level of detail (more information on this in the next section).
- Whenever you use multiple partitions for a given measure group, you must ensure that you update the data statistics for each partition. More specifically, it is important to ensure that the partition data and member counts accurately reflect the specific data in the partition and not the data across the entire measure group. For more information on how to update partition counts, see Specifying statistics about cube data.
- For distinct count measure groups, consider specifically defining your partitions to optimize the processing and query performance of distinct counts. For more information on this topic, see Optimizing distinct count.
Aggregation considerations for multiple partitions
For each partition, you can use a different aggregation design. By taking advantage of this flexibility, you can identify those data sets that require higher aggregation design. While the flexibility can definitely help you enhance performance, too many aggregation designs across your partitions can introduce overhead.
To help guide your aggregation design, the following are general guidelines for you to consider. When you have less than ten partitions, you should typically have no more than two aggregation designs per measure group. With less than 50 partitions, you typically want no more than three aggregation designs per measure group. For greater than 50 partitions, you want no more than four aggregation designs.
While each partition can have a different aggregation design, it is a good practice to group your partitions based on the data statistics of the partition so that you can apply a single aggregation design to a group of similar partitions.
Consider the following example. In a cube with multiple monthly partitions, new data may flow into the single partition corresponding to the latest month. Generally that is also the partition most frequently queried. A common aggregation strategy in this case is to perform Usage-Based Optimization to the most recent partition, leaving older, less frequently queried partitions as they are.
The newest aggregation design can also be copied to a base partition. This base partition holds no data—it serves only to hold the current aggregation design. When it is time to add a new partition (for example, at the start of a new month), the base partition can be cloned to a new partition. When the slice is set on the new partition, it is ready to take data as the current partition. Following an initial full process, the current partition can be incrementally updated for the remainder of the period. For more information on processing techniques, see Refreshing partitions efficiently.
Writing efficient MDX
When the Query Execution Engine executes an MDX query, it translates the query into Storage Engine data requests and then compiles the data to produce a query result set.
During query execution, the Query Execution Engine also executes any calculations that are directly or indirectly referenced, such as calculated members, semi-additive measures, and MDX Script scope assignments. Whenever you directly or indirectly reference calculations in your query, you must consider the impact of the calculations on query performance.
This section presents techniques for writing efficient MDX statements in common design scenarios. The section assumes that the reader has some knowledge of MDX.
Specifying the calculation space
When you need to create MDX calculations that apply business rules to certain cells in a cube, it is critical to write efficient MDX code that effectively specifies the calculation space for each rule.
Before you learn about these MDX coding techniques, it is important to be familiar with some common scenarios where conditional business rules are relevant. Following is a description of a growth calculation where you want to apply unique rules to different time periods. To calculate growth from a prior period, you may think that the logical expression for this calculation is current period minus prior period. In general, this expression is valid; however, it is not exactly correct in the following three situations.
- The First Period—In the first time period of a cube, there is no prior period. Since the prior period does not exist for the first period, the expression of current period minus prior period evaluates to current period, which can be somewhat misleading. To avoid end-user confusion, for the prior period, you may decide to apply a business rule that replaces the calculation with NULL.
- The All Attribute—You need to consider how the calculation interacts with the All. In this scenario, the calculation simply does not apply to the All, so you decide to apply a rule that sets the value for All to NA.
- Future Periods—For time periods that extend past the end of the data range, you must consider where you want the calculation to stop. For example, if your last period of data is December of 2006, you want to use a business rule to only apply the calculation to time periods before and including December of 2006.
Based on this analysis, you need to apply four business rules for the growth from prior period calculation. Rule 1 is for the first period, rule 2 is for the All, rule 3 is for the future time periods and rule 4 is for the remaining time periods. The key to effectively applying these business rules is to efficiently identify the calculation space for each rule. To accomplish this, you have two general design choices:
- You can create a calculated member with an IIF statement that uses conditional logic to specify the calculation space for a given period.
- Alternatively you can create a calculated member and use an MDX Script scope assignment to specify the calculation space for a given period.
In a simple cube with no other calculations, the performance of these two approaches is approximately equal. However, if the calculated member directly or indirectly references any other MDX calculations such as semi-additive measures, calculated members, or MDX Script scope assignments, you can definitely see a performance difference between the two approaches. To see how MDX Script scope assignments can be used to perform the growth calculation, you can use the Business Intelligence Wizard to generate time intelligence calculations in your cube.
To better understand the performance benefit of the scope assignment technique used by the Business Intelligence Wizard, consider the following illustrative example of an effective scope assignment. You require a new calculated member called Weekend Gross Profit. The Weekend Gross Profit is derived from the Gross Profit calculated member. To calculate the Weekend Gross Profit, you must sum the Gross Profit calculated member for the days in a sales weekend. This seems easy enough but there are different business rules that apply to each sales territory to as follows:
- For all of the stores in the North America sales territory, the Weekend Gross Profit should sum the Gross Profit for days 5, 6, and 7, i.e., Friday, Saturday, and Sunday.
- For all of the stores in the Pacific sales territory, the Weekend Gross Profit should be NULL. You want to set it to NULL because the Pacific territory is in the process of closing of all of its stores and the Gross Profit numbers are significantly skewed due to their weekend clearance sales.
- For all other territories, the Weekend Gross Profit should sum the Gross Profit for days 6 and 7, i.e., Saturday and Sunday.
To satisfy the conditions of this scenario, following are two design options that you can choose.
Option 1—Calculated Member
You can use a calculated member with an IIF statement to apply the conditional summing of Gross Profit. In this scenario, the Query Execution Engine must evaluate the calculation space at runtime on a cell-by-cell basis based on the IIF specification. As a result, the Query Execution Engine uses a less optimized code path to execute the calculation that increases query response time.
with member [Option 1 Weekend Gross Profit] as
iif (ancestor([Sales Territory].[Sales Territory].CurrentMember,
[Sales Territory].[Sales Territory].[Group])
IS [Sales Territory].[Sales Territory].[Group].&[North America],
Sum({[Date].[Day of Week].&[5],
[Date].[Day of Week].&[6],
[Date].[Day of Week].&[7]},
[Measures].[Reseller Gross Profit]),
iif (ancestor([Sales Territory].[Sales Territory].CurrentMember,
[Sales Territory].[Sales Territory].[Group])
IS [Sales Territory].[Sales Territory].[Group].&[Pacific],
NULL,
Sum({[Date].[Day of Week].&[6],
[Date].[Day of Week].&[7]},
[Measures].[Reseller Gross Profit])))
Option 2—Scope assignment with a Calculated Member
In Option 2, you use a calculated member with a scope assignment to apply the conditional summing of Gross Profit.
CREATE MEMBER CURRENTCUBE.[MEASURES].[Option 2 Weekend Gross Profit] AS
Sum({[Date].[Day of Week].&[7],
[Date].[Day of Week].&[6] },
[Measures].[Reseller Gross Profit]);
Scope ([Option 2 Weekend Gross Profit],
Descendants([Sales Territory].[Sales Territory Group].&[North
America]));
This = Sum({[Date].[Day of Week].&[7],
[Date].[Day of Week].&[6],
[Date].[Day of Week].&[5] },
[Measures].[Reseller Gross Profit]);
End Scope;
Scope ([Option 2 Weekend Gross Profit],
Descendants([Sales Territory].[Sales Territory Group].&[Pacific]));
This = NULL;
End Scope;
In this example, this option is significantly faster than the first option. The reason this option is faster is because the two scope subcube definitions (the left hand side of each scope assignment) enable the Query Execution Engine to know ahead of time the calculation space for each business rule. Using this information, the Query Execution Engine can select an optimized execution path to execute the calculation on the specified range of cells. As a general rule, it is a best practice to always try to simplify calculation expressions by moving the complex parts into multiple Scope definitions whenever possible.
Note that in this Scope assignment, the Descendants function represents the Analysis Services 2000 approach to using MDX functions to navigate a dimension hierarchy. An alternative approach in Analysis Services 2005 is to simply use Scope with the attribute hierarchies. So instead of using Scope (Descendants([Sales Territory].[Pacific])), you can use Scope ([Sales Territory].[Pacific]).
To enhance performance, wherever possible, use the scope subcube definition to narrowly define the calculation space. While this is the ideal scenario, there are situations where it is not possible. The most common scenario is when you need to define a calculation on an arbitrary collection of cells ([Measures].[Reseller Sales Amount] >500). This type of expression is not allowed in the scope subcube definition since the definition must be static. In this scenario, the solution is to define a broader calculation space in the scope definition, and then use the scope MDX expression (the right hand side of the scope assignment) to narrow down the cube space using the IIF statement. The following is an example of how this statement can be structured to apply a weighting factor to the North American sales:
SCOPE ([Measures].[Sales Amount],
[Sales Territory].[Sales Territory].[Group].&[North America])
THIS =
IIF ([Measures].[Sales Amount] > 1000, [Measures].[Sales Amount],
[Measures].[Sales Amount]*1.2);
END SCOPE
From a performance perspective, MDX scope assignments provide an efficient alternative to using IIF to apply unique business rules to certain cells in a cube. Whenever you need to conditionally apply calculations, you should consider this approach.
Removing empty tuples
When you write MDX statements that use a set function such as Crossjoin, Descendants, or Members, the default behavior of the function is to return both empty and nonempty tuples. From a performance perspective, empty tuples can not only increase the number of rows and/or columns in your result set, but they can also increase query response time.
In many business scenarios, empty tuples can be removed from a set without sacrificing analysis capabilities. Analysis Services provides a variety of techniques to remove empty tuples depending on your design scenario.
Analysis Services ground rules for interpreting null values
Before describing these techniques, it is important to establish some ground rules about how empty values are interpreted in various design scenarios.
- Missing fact table records—Earlier in the white paper, it was stated that only records that are present in the relational fact table are stored in the partition. For example, a sales fact table only stores records for those customers with sales for a particular product. If a customer never purchased a product, a fact table record will not exist for that customer and product combination. The same holds true for the Analysis Services partition. If a fact table record does not exist for a particular combination of dimension members, the cube cells for these dimension members are considered empty.
- Null values in measures—For each fact table measure that is loaded into the partition, you can decide how Analysis Services interprets null values. Consider the following example. Your sales fact table contains a record that has a sales amount of 1000 and a discount amount of null. When discount is loaded into the cube, by default it is interpreted as a zero, which means that it is not considered empty. How Analysis Services interprets null values is controlled by a property called NullProcessing. The NullProcessing property is set on a measure-by-measure basis. By default, it is set to Automatic which means that Analysis Services converts the null values to zero. If you want to preserve the null value from the source system, such as in the example of the discount measure, configure the NullProcessingProperty of that measure to Preserve instead of Automatic.
- Null values in calculations—In calculations, it is important to understand how Nulls are evaluated. For example, 1 minus Null equals 1, not Null. In this example, the Null is treated like a zero for calculation purposes. which may or may not be what you want to use. To explicitly test whether a tuple is null, use the ISEmpty function within an IIF statement to conditionally handle empty tuples.
-
Empty members—When writing calculations that reference dimension members, you may need to handle scenarios where specific members do not exist, such as the parent of the All. In this scenario, the ISEmpty function is not appropriate as it tests for empty cells. Rather in this scenario you want to use the IS operator to test whether the member IS NULL.
General techniques for removing empty tuples
The following describes the most general techniques for removing empty tuples:
-
Non Empty Keyword—When you want to remove empty rows or columns from the axes of an MDX query, you can use the NON EMPTY keyword. Most client applications use the NON EMPTY keyword to remove empty cells in query result sets. The NON EMPTY keyword is applied to an axis and takes effect after the query result set is determined, i.e., after the Query Execution Engine completes the axis tuples with the current members taken from the rows axis, columns axis, and WHERE clause (as well as the default members of the attribute hierarchies not referenced in the query).
Consider the following example displayed in Figure 18. Note that only a subset of the query results is shown.
Figure 18 – Query without Non Empty Keyword
In Figure 18, the rows axis returns a complete list of resellers, regardless of whether or not they have sales in 2003. For each reseller, the columns axis displays the reseller’s 2003 sales. If the reseller had no sales in 2003, the reseller is still returned in the list, it is just returned with a (null) value.
To remove resellers who do not have sales in 2003, you can use the NON EMPTY keyword as displayed in Figure 19. Note that only a subset of the query results is shown.
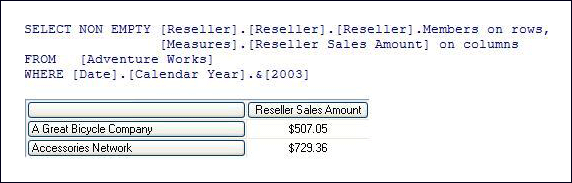
Figure 19 – Query with Non Empty Keyword
In Figure 19, the NON EMPTY keyword removes the resellers that do not have sales, i.e., null sales for 2003. To apply the NON EMPTY keyword, the Query Execution Engine must completely evaluate all cells in the query before it can remove the empty tuples.
If the query references a calculated member, the Query Execution Engine must evaluate the calculated member for all cells in the query and then remove the empty cells. Consider the example displayed in Figure 20. Note that only a subset of the query results is shown. In this example, you have modified the reseller query, replacing Reseller Sales Amount with the calculated measure Prior Year Variance. To produce the query result set, Analysis Services first obtains a complete set of resellers and then removes those resellers that have an empty prior year variance.
Figure 20 – Query with Non Empty Keyword and Calculated Measure
Given the ground rules about null interpretation, it is necessary to point out when the prior year variance is going to be null.
- Acceptable Sales & Service has no sales in 2003 but has sales of $838.92 in 2002. The Prior Year Variance calculation is null minus $838.92 which evaluates to -$838.92. Since the value is not null, that reseller is returned in the result set.
- Accessories Network has $729.36 sales in 2003 but no sales in 2002. The Prior Year Variance calculation is $729.36 minus null which evaluates to $729.36. Since the value is not null, the reseller is returned in the result set.
- If a reseller has no sales in either 2003 or 2002, the calculation is null minus null, which evaluates to null. The reseller is removed from the result set.
-
NonEmpty Function—The NonEmpty function, NonEmpty(), is similar to the NON EMPTY keyword but it provides additional flexibility and more granular control. While the NON EMPTY keyword can only be applied to an axis, the NonEmpty function can be applied to a set. This is especially useful when you are writing MDX calculations.
As an additional benefit, the NonEmpty function allows you use an MDX expression to evaluate the empty condition against a business rule. The business rule can reference any tuple, including calculated members. Note that if you do not specify the MDX expression in the NonEmpty function, the NonEmpty function behaves just like the NON EMPTY keyword, and the empty condition is evaluated according to the context of the query.
Continuing with the previous examples regarding resellers, you want to change the previous queries to apply your own business rule that decides whether or not a reseller is returned in the query. The business rule is as follows. You want a list of all resellers that had a sale in 2002. For each of these resellers, you only want to display their sales for 2003. To satisfy this requirement, you use the query displayed in Figure 21. Note that only a subset of the query results is shown.
Figure 21 Query with NonEmpty Function
In this query, the NonEmpty function returns those resellers that had a sale in 2002. For each of these resellers, their 2003 sales are displayed. Note that query produces a different list of resellers than the resellers returned in the NON EMPTY keyword example. The Accessories Network reseller has been removed because it only has sales in 2003 with no sales in 2002.
Note that an alternative way to write this query is to use the FILTER expression, such as the following:
SELECT FILTER ([Reseller].[Reseller].[Reseller].Members,
NOT ISEmpty(([Measures].[Reseller Sales Amount],
[Date].[Calendar Year].&[2002]))) on rows,
[Measures].[Reseller Sales Amount] on columns
FROM [Adventure Works]
WHERE [Date].[Calendar Year].&[2003]
In this query, FILTER is used to return only those resellers who had a sale in 2002. FILTER was commonly used in prior versions of Analysis Services. For simple expressions like the one depicted in the above example, Analysis Services actually re-writes the query behind-the-scenes using the NonEmpty function. For other more complicated expressions, it is advisable to use the NonEmpty function in place of the FILTER expression. In Analysis Services 2005, the NonEmpty function provides a more optimized alternative to using the FILTER expression to check for empty cells.
As you use NON EMPTY keyword and NonEmpty function to remove empty tuples, consider the following guidelines:
- The NonEmpty function and NON EMPTY keyword will have approximately the same performance when the parameters passed to NonEmpty function coincide with the query axes of a NON EMPTY keyword query.
- In common scenarios, Non Empty is normally used instead of NonEmpty() at the top level of SELECT query axes.
- In calculations or query sub expressions, NonEmpty() is the recommended approach to achieve similar semantics. When using NonEmpty(), pay extra attention to making sure that the current cell context used by NonEmpty() is the intended one, possibly by specifying additional sets and members as the second parameter of the function.
-
Non_Empty_Behavior (NEB)—Whether or not an expression resolves to null is important for two major reasons. First, most client applications use the NON EMPTY key word in a query. If you can tell the Query Execution Engine that you know an expression will evaluate to null, it does not need to be computed and can be eliminated from the query results before the expression is evaluated. Second, the Query Execution Engine can use the knowledge of a calculation’s Non_Empty_Behavior (NEB) even when the NON EMPTY keyword is not used. If a cell’s expression evaluates to null, it does not have to be computed during query evaluation.
Note that the current distinction between how the Query Execution Engine uses an expression’s NEB is really an artifact of the Query Execution Engine design. This distinction indicates whether one or both optimizations are used, depending how the NEB calculation property is defined. The first optimization is called NonEmpty Optimization and the second optimization is called Query Execution Engine Optimization.
When an expression’s NEB is defined, the author is guaranteeing that the result is null when the NEB is null and consequently the result set is not null when NEB is not null. This information is used internally by the Query Execution Engine to build the query plan.
To use NEB for a given calculation, you provide an expression that defines the conditions under which the calculation is guaranteed to be empty. The reason why NEB is an advanced setting is because it is often difficult to correctly identify the conditions under which the calculation is guaranteed to be empty. If you incorrectly set NEB, you will receive incorrect calculation results. As such, the primary consideration of using NEB is to ensure first and foremost that you have defined the correct expression, before taking into account any performance goals.
The NEB expression can be a fact table measure, a list of two or more fact table measures, a tuple, or a single measure set. To help you better understand which optimizations are used for each expression; consider the guidelines in Table 2.
Table 2 NEB guidelines
|
Calculation Type
|
NEB
Expressions
|
Query Execution Engine Optimization Support
|
NonEmpty Optimization Support
|
Example
|
|
Calculated Measure
|
Constant measure
|
Yes
|
Yes
|
With Member Measures.DollarSales As Measures.Sales / Measures.ExchangeRate,
NEB = Measures.Sales
|
|
Calculated Measure
|
(List of two or more constant measure references)
|
No
|
Yes
|
With Member Measures.Profit As Measures.Sales – Measures.Cost,
NEB = {Measures.Sales, Measures.Cost}
|
|
Any (calculated member, script assignment, calculated cell)
|
Constant tuple reference
Constant single-measure set
|
Yes
|
No
|
Scope [Measures].[store cost];
This = iif( [Measures].[Exchange Rate]>0, [Measures].[Store Cost]/[Measures].[Exchange Rate], null );
Non_Empty_Behavior(This) = [Measures].[Store Cost];
End Scope;
|
In addition to understanding the guidelines for the NEB expression, it is important to consider how the expression is applied for various types of calculation operations.
-
Scenario 1—Addition or Subtraction: Example – Measures.M1 + or – Measures.M2. The following guidelines apply for addition and subtraction:
- In general, you MUST specify both measures in the NEB expression for correctness reasons.
- In particular, if both measures belong to the same measure group, it may be possible to specify just one of them in NEB expression if the data supports it. This could result in better performance.
-
Scenario 2—Multiplication. Example – Measures.M1 * Measures.M2. The following guidelines apply for multiplication:
- In general, you CANNOT specify any correct NEB expression for this calculation.
- In particular, if it is guaranteed that one of the measures is never null (e.g., a currency exchange rate), you MAY specify the other measure in NEB expression.
- In particular, if it is guaranteed that, for any given cell, either both measures are null, or both are non-null (e.g. they belong to the same measure group), you MAY specify both measures in the NEB expression, OR specify a single measure.
- Scenario 3—Division. Example – Measures.M1 / Measures.M2. In this scenario, you MUST specify the first measure (the numerator, M1) in NEB.
Evaluating empty by using a measure group
In some design scenarios, you may be able to optimize the removal of empty tuples by evaluating the empty condition against an entire measure group. In other words, if a tuple corresponds to a fact data record in the measure group, the tuple is included. If the tuple does not have a fact data record, it is excluded. To apply this syntax, you can use a special version of the Exists function, Exists (Set,, “Measure Group”). Note that this special version of the Exists function actually behaves very differently from the regular Exists function and includes a third parameter of type string where you can specify the name of the desired measure group.
While this approach can be very powerful in removing empty tuples, you must evaluate whether it generates the correct result set. Consider the following example. The sales fact table contains a record corresponding to a reseller’s purchase. In this record, Sales Amount has a value of 500 while Discount Amount is null. To write a query where you only see the resellers with discounts, you cannot use this approach since the reseller still exists in measure group whether or not the reseller’s Discount Amount is null. To satisfy this query, you will need to use the NON EMPTY keyword or NonEmpty function as long as you have properly configured the Null Processing property for the measures in that measure group.
When you do have scenarios where you can apply the Exists function, keep in mind that the Exists function ignores all calculated members. In addition, note that the Exists function used with a measure group specification replaces the deprecated NonEmptyCrossJoin function, which was used in prior versions of Analysis Services to achieve similar functionality.
Removing empty member combinations
Analysis Services 2005 provides a rich attribute architecture that allows you to analyze data across multiple attributes at a given time. When you write queries that involve multiple attributes, there are some optimizations that you should be aware of to ensure that the queries are efficiently evaluated.
- Autoexists—Autoexists is applied behind the scenes whenever you use the Crossjoin function to cross join two attribute hierarchies from the same dimension or, more broadly speaking, whenever you Crossjoin sets with common dimensionality. Autoexists retains only the members that exist with each other so that you do not see empty member combinations that never occur such as (Seattle, Scotland). In some design scenarios, you may have a choice as to whether you create two attributes in a given dimension or model them as two separate dimensions. For example, in an employee dimension you may consider whether or not you should include department in that dimension or add department as another dimension. If you include department in the same dimension, you can take advantage of Autoexists to remove empty combinations of employees and departments.
- Exists function—Using the Exists function in the form of Exists (Set1, Set2), you can remove tuples from one set that do not exist in another set by taking advantage of Autoexists. For example, Exists (Customer.Customer.Members, Customer.Gender.Male) only returns male customers.
- EXISTING operator—The EXISTING operator is similar to the Exists function but it uses as the filter set, the current coordinate specified in your MDX query. Since it uses the current coordinate, it reflects whatever you are slicing by in your query.
In Figure 22, a calculated measure counts a set of customers defined by the EXISTING operator and the WHERE clause of the query slices on Male customers. The result set of this query is a total count of male customers.
Figure 22 Calculated Measure Using Existing Operator
Summarizing data with MDX
Analysis Services naturally aggregates measures across the attributes of each dimension. While measures provide tremendous analytical value, you may encounter scenarios when you want to perform additional aggregations of data, either aggregating MDX calculations or aggregating subsets of the cube that satisfy specific business rules.
Consider the following examples where you may need to aggregate data in MDX:
- Performing time series analysis—You need
to sum reseller profit for all time periods in this year up to and include the current time period.
- Aggregating custom sets—You need to average year-over-year sales variance across all resellers in the USA who sold more than 10,000 units.
- Aggregating calculations at dimension leaves—You need to aggregate the hours worked by each employee multiplied by the employee’s hourly rate.
While using MDX calculated measures with functions like Sum, Average, and Aggregate is a valid approach to summarizing data in these scenarios, from a performance perspective, summarizing data through MDX is not a trivial task and can potentially result in slow performance in large-scale cubes or cubes with many nested MDX calculations. If you experience performance issues summarizing data in MDX, you may want to consider the following design alternatives:
Create a named calculation in the data source view
Depending on the scenario, you should first consider whether you need to perform additional aggregations in MDX or whether you can take advantage of the natural aggregation of the cube. Consider the Profit Margin calculation. Profit is defined by Revenue minus Cost. Assuming that these two measures are stored in the same fact table, instead of defining a calculated member that is calculated on the fly, you can move the Profit calculation to a measure. In the data source view you can create a named calculation on the fact table that defines Profit as Revenue minus Cost. Then, you can add the named calculation as a measure in your cube to be aggregated just like every other measure.
Generally speaking, any time that you have a calculated member that performs addition and subtraction from columns on the same fact table, you can move the calculation to measure. If you do this, keep in mind that SQL operations on NULL data are not identical to MDX. In addition, even though you can add the calculation to the fact table, you must also evaluate the impact of additional measures on the cube. Whenever you query a measure group, even if you only request one measure, all measures in that measure group are retrieved from the Storage Engine and loaded into the data cache. The more measures you have, the greater the resource demands. Therefore, it is important to evaluate the performance benefits on a case by case basis.
Use measure expressions
Measure expressions are calculations that the Storage Engine can perform. Using
measure expressions, you can multiply or divide data from two different measure groups at the measure group leaves and then aggregate the data as a part of normal cube processing. The classic example of this is when you have a weighting factor stored in one measure group, such as currency rates, and you want to apply that to another measure group such as sales. Instead of
creating an MDX calculation that aggregates the multiplication of these two measures at the measure group leaves, you can use measure expressions as an optimized solution. This kind of calculation is perfect for a measure expression since it is somewhat more difficult to accomplish in the data source view given that the measures are from different source fact tables and likely have different granularities. To perform the calculation in the data source view, you can use a named query to join the tables; however, the measure expression typically provides a more efficient solution.
While measure expressions can prove to be very useful, note that when you use a measure expression, the Storage Engine evaluates the expression in isolation of the Query Execution Engine. If any of the measures involved in the measure expression depend on MDX calculations, the Storage Engine evaluates the measure expressions without any regard for the MDX calculations, producing an incorrect result set. In this case, rather than using a measure expression, you can use a calculated member or scope assignment.
Use semiadditive measures and unary operators
Instead of writing complex MDX calculations to handle semiadditive measures, you can use the semiadditive aggregate functions like FirstChild, LastChild, etc. Note that semiadditive functions are a feature of SQL Server Enterprise Edition. In addition to using semiadditive measures, in finance applications, instead of writing complicated MDX expressions that apply custom aggregation logic to individual accounts, you can use unary operators with parent-child hierarchies to apply a custom roll up operator for each account. Note that while parent-child hierarchies are restricted in their aggregation design, they can be faster and less complex than custom MDX. For more information on parent-child hierarchies, see Parent-child hierarchies in this white paper.
Move numeric attributes to measures
You can
convert numeric attributes to measures whenever you have an attribute such as Population or Salary that you need to aggregate. Instead of writing MDX expressions to aggregate these values, consider defining a separate measure group on the dimension table containing the attribute and then defining a measure on the attribute column. So for example, you can replace Sum(Customer.City.Members, Customer.Population.MemberValue) by adding a new measure group on the dimension table with a Sum measure on the Population column.
Aggregate subsets of data
In many scenarios, you want to aggregate subsets of data that meet specific business rules. Before you write a complex filter statement to identify the desired set, evaluate whether you can substitute a filter expression by using Crossjoin or Exists with specific members of your attribute hierarchies.
Consider the following examples.
-
If you want a set of resellers with 81 to 100 employees and you have the number of employees stored in a separate attribute, you can easily satisfy this request with the following syntax:
Exists([Reseller].[Reseller].members,
[Reseller].[Number of Employees].[81]:
[Reseller].[Number of Employees].[100])
In this example, you use Exists with a range for the Number of Employees attribute hierarchy to filter resellers in the 81–100 employee range. The value of this approach is that you can arbitrarily set the ranges based on user requests.
-
If your reseller dimension is large and the ranges that you need to calculate are fixed and commonly used across all users, you can pre-build an attribute that groups the resellers according to employee size ranges. With this new attribute, the previous statement could be written as follows:
Exists([Reseller].[Reseller].members,
[Reseller].[Employee Size Range].[81 to 100])
-
Now if you want the sum of the gross profit for resellers with 81 to 100 employees, you can satisfy this request with the following solutions.
For the range of values, you can use the following syntax.
Sum([Reseller].[Number of Employees].[81]:
[Reseller].[Number of Employees].[100],
[Measures].[Reseller Gross Profit])
For the custom range attribute, you can use the following syntax.
([Reseller].[Number of Employees].[81 – 100],
[Measures].[Reseller Gross Profit])
Note that in both of these solutions, the set of resellers is not necessary.
Using an attribute hierarchy to slice data sets provides a superior solution to aggregating a set filtered on member property values, which was a common practice in prior versions of Analysis Services. Retrieving a member’s properties can be slow since each member needs to be retrieved as well as its property value. With attribute hierarchies, you can leverage the normal aggregation of the cube.
Taking advantage of the Query Execution Engine cache
During the execution of an MDX query, the Query Execution Engine stores calculation results in the Query Execution Engine cache. The primary benefits of the cache are to optimize the evaluation of calculations and to support the re-usage of calculation results across users. To understand how the Query Execution Engine uses calculation caching during query execution, consider the following example. You have a calculated member called Profit Margin. When an MDX query requests Profit Margin by Sales Territory, the Query Execution Engine caches the Profit Margin values for each Sales Territory, assuming that the Sales Territory has a nonempty Profit Margin. To manage the re-usage of the cached results across users, the Query Execution Engine uses scopes. Note that Query Execution scopes should not be confused with the SCOPE keyword in an MDX script. Each Query Execution Engine scope maintains its own cache and has the following characteristics.
- Query
Scope—The query scope contains any calculations created within a query by using the WITH keyword. The query scope is created on demand and terminates when the query is over. Therefore, the cache of the query scope is not shared across queries in a session.
- Session
Scope—The session scope contains calculations created in a given session by using the CREATE statement. The cache of the session scope is reused from request to request in the same session, but is not shared across sessions.
- Global Scope—The global scope contains the MDX script, unary operators, and custom rollups for a given set of security permissions. The cache of the global scope can be shared across sessions if the sessions share the same security roles.
The scopes are tiered in terms of their level of re-usage. The query scope is considered to be the lowest scope, because it has no potential for re-usage. The global scope is considered to be the highest scope, because it has the greatest potential for re-usage.
During execution, every MDX query must reference all three scopes to identify all of the potential calculations and security conditions that can impact the evaluation of the query. For example, if you have a query that contains a query calculated member, to resolve the query, the Query Execution Engine creates a query scope to resolve the query calculated member, creates a session scope to evaluate session calculations, and creates a global scope to evaluate the MDX script and retrieve the security permissions of the user who submitted the query. Note that these scopes are created only if they aren’t already built. Once they are built for a session, they are usually just re-used for subsequent queries to that cube.
Even though a query references all three scopes, it can only use the cache of a single scope. This means that on a per-query basis, the Query Execution Engine must select which cache to use. The Query Execution Engine always attempts to use the cache of the highest possible scope depending on whether or not the Query Execution Engine detects the presence of calculations at a lower scope.
If the Query Execution Engine detects any calculations that are created at the query scope, it always uses the query scope cache, even if a query references calculations from the global scope. If there are no query-scope calculations, but there are session-scope calculations, the Query Execution Engine uses the cache of session scope. It does not matter whether or not the session calculations are actually used in a query. The Query Execution Engine selects the cache based on the presence of any calculation in the scope. This behavior is especially relevant to users with MDX-generating front-end tools. If the front-end tool creates any session scoped calculations, the global cache is not used, even if you do not specifically use the session calculation in a given query.
There are other calculation scenarios that impact how the Query Execution Engine caches calculations. When you call a stored procedure from an MDX calculation, the engine always uses the query cache. This is because stored procedures are nondeterministic. This means that there is no guarantee of what the stored procedure will return. As a result, nothing will be cached globally or in the session cache. Rather, the calculations will only be stored in the query cache. In addition, the following scenarios determine how the Query Execution Engine caches calculation results:
- If you enable visual totals for the session by setting the default MDX Visual Mode property of the Analysis Services connection string to 1, the Query Execution Engine uses the query cache for all queries issued in that session.
- If you enable visual totals for a query by using the MDX VisualTotals function, the Query Execution Engine uses the query cache.
- Queries that use the subselect syntax (SELECT FROM SELECT) or are based on a session subcube (CREATE SUBCUBE) could cause the query cache to be used.
- Arbitrary shape sets can only use the query cache when they are used in a subselect, in the WHERE clause, or in a calculated member Aggregate expression referenced in the WHERE clause. An example of arbitrary shape set is a set of multiple members from different levels of a parent-child hierarchy.
Based on this behavior, when your querying workload can benefit from re-using data across users, it is a good practice to define calculations in the global scope. An example of this scenario is a structured reporting workload where you have a few security roles. By contrast, if you have a workload that requires individual data sets for each user, such as in an HR cube where you have a many security roles or you are using dynamic security, the opportunity to re-use calculation results across users is lessened and the performance benefits associated with re-using the Query Execution Engine cache are not as high.
Applying calculation best practices
While many MDX recommendations must be evaluated in the context of a design scenario, the following best practices are optimization techniques that apply to most MDX calculations regardless of the scenario.
Use the Format String property
Instead of applying conditional logic to return customized values if the cell is EMPTY or 0, use the Format String property. The Format String property provides a mechanism to format the value of a cell. You can specify a user-defined formatting expression for positive values, negative values, zeros, and nulls. The Format String display property has considerably less overhead than writing a calculation or assignment that must invoke the Query Execution Engine. Keep in mind that your front-end tool must support this property.
Avoid late-binding functions
When writing MDX calculations against large data sets involving multiple iterations, avoid referencing late binding functions whose metadata cannot be evaluated until run time. Examples of these functions include: LinkMember, StrToSet, StrToMember, StrToValue, and LookupCube. Because they are evaluated at run time, the Query Execution Engine cannot select the most efficient execution path.
Eliminate redundancy
When you use a function that has default arguments such as Time.CurrentMember, you can experience performance benefits if you do not redundantly specify the default argument. For example, use PeriodsToDate([Date].[Calendar].[Calendar Year]) instead of PeriodsToDate([Date].[Calendar].[Calendar Year], [Date].Calendar.CurrentMember). To take advantage of this benefit, you must ensure that you only have one default Time Hierarchy in your application. Otherwise, you must explicitly specify the member in your calculation.
Ordering expression arguments
When writing calculation expressions like “expr1 * expr2”, make sure the expression sweeping the largest area/volume in the cube space and having the most Empty (Null) values is on the left side. For instance, write “Sales * ExchangeRate” instead of “ExchangeRate * Sales”, and “Sales * 1.15” instead of “1.15 * Sales”. This is because the Query Execution Engine iterates the first expression over the second expression. The smaller the area in the second expression, the fewer iterations the Query Execution Engine needs to perform, and the faster the performance.
Use IS
When you need to check the value of a member, use IIF [Customer].[Company] IS [Microsoft] and not IIF [Customer].[Company].Name = “Microsoft”. The reason that IS is faster is because the Query Execution Engine does not need to spend extra time translating members into strings.
Tuning Processing Performance
Processing is the general operation that loads data from one or more data sources into one or more Analysis Services objects. While OLAP systems are not generally judged by how fast they process data, processing performance impacts how quickly new data is available for querying. While every application has different data refresh requirements, ranging from monthly updates to “near real-time” data refreshes, the faster the processing performance, the sooner users can query refreshed data.
Note that “near real-time” data processing is considered to be a special design scenario that has its own set of performance tuning techniques. For more information on this topic, see Near real-time data refreshes.
To help you effectively satisfy your data refresh requirements, the following provides an overview of the processing performance topics that are discussed in this section:
Understanding the processing architecture – For readers unfamiliar with the processing architecture of Analysis Services, this section provides an overview of processing jobs and how they apply to dimensions and partitions. Optimizing processing performance requires understanding how these jobs are created, used, and managed during the refresh of Analysis Services objects.
Refreshing dimensions efficiently – The performance goal of dimension processing is to refresh dimension data in an efficient manner that does not negatively impact the query performance of dependent partitions. The following techniques for accomplishing this goal are discussed in this section: optimizing SQL source queries, reducing attribute overhead, and preparing each dimension attribute to efficiently handle inserts, updates, deletes as necessary.
Refreshing partitions efficiently – The performance goal of partition processing is to refresh fact data and aggregations in an efficient manner that satisfies your overall data refresh requirements. The following techniques for accomplishing this goal are discussed in this section: optimizing SQL source queries, using multiple partitions, effectively handling data inserts, updates, and deletes, and evaluating the usage of rigid vs. flexible aggregations.
Understanding the processing architecture
Processing is typically described in the simple terms of loading data from one or more data sources into one or more Analysis Services objects. While this is generally true, Analysis Services provides the ability to perform a broad range of processing operations to satisfy the data refresh requirements of various server environments and data configurations.
Processing job overview
To manage processing operations, Analysis Services uses centrally controlled jobs. A processing job is a generic unit of work generated by a processing request. Note that while jobs are a core component of the processing architecture, jobs are not only used during processing. For more information on how jobs are used during querying, see Job architecture.
From an architectural perspective, a job can be broken down into parent jobs and child jobs. For a given object, you can have multiple levels of nested jobs depending on where the object is located in the database hierarchy. The number and type of parent and child jobs depend on 1) the object that you are processing such as a dimension, cube, measure group, or partition, and 2) the processing operation that you are requesting such as a ProcessFull, ProcessUpdate, or ProcessIndexes. For example, when you issue a ProcessFull for a measure group, a parent job is created for the measure group with child jobs created for each partition. For each partition, a series of child jobs are spawned to carry out the ProcessFull of the fact data and aggregations. In addition, Analysis Services implements dependencies between jobs. For example, cube jobs are dependent on dimension jobs.
The most significant opportunities to tune performance involve the processing jobs for the core processing objects: dimensions and partitions.
Dimension processing jobs
During the processing of MOLAP dimensions, jobs are used to extract, index, and persist data in a series of dimension stores. For more information on the structure and content of the dimension stores, see Data retrieval: dimensions. To create these dimension stores, the Storage Engine uses the series of jobs displayed in Figure 23.

Figure 23 Dimension processing jobs
Build attribute stores
For each attribute in a dimension, a job is instantiated to extract and persist the attribute members into an attribute store. As stated earlier, the attribute store primarily consists of the key store, name store, and relationship store. While Analysis Services is capable of processing multiple attributes in parallel, it requires that an order of operations must be maintained. The order of operations is determined by the attribute relationships in the dimension. The relationship store defines the attribute’s relationships to other attributes. In order for this store to be built correctly, for a given attribute, all dependent attributes must already be processed before its relationship store is built. To provide the correct workflow, the Storage Engine analyzes the attribute relationships in the dimension, assesses the dependencies among the attributes, and then creates an execution tree that indicates the order in which attributes can be processed, including those attributes that can be processed in parallel.
Figure 24 displays an example execution tree for a Time dimension. The solid arrows represent the attribute relationships in the dimension. The dashed arrows represent the implicit relationship of each attribute to the All attribute. Note that the dimension has been configured using cascading attribute relationships which is a best practice for all dimension designs.

Figure 24 Execution tree example
In this example, the All attribute proceeds first, given that it has no dependencies to another attribute, followed by the Fiscal Year and Calendar Year attributes, which can be processed in parallel. The other attributes proceed according to the dependencies in the execution tree with the primary key attribute always being processed last since it always has at least one attribute relationship, except when it is the only attribute in the dimension.
The time taken to process an attribute is generally dependent on 1) the number of members and 2) the number of attribute relationships. While you cannot control the number of members for a given attribute, you can improve processing performance by using cascading attribute relationships. This is especially critical for the key attribute since it has the most members and all other jobs (hierarchy, decoding, bitmap indexes) are waiting for it to complete. For more information about the importance of using cascading attribute relationships, see Identifying attribute relationships.
Build decoding stores
Decoding stores are used extensively by the Storage Engine. During querying, they are used to retrieve data from the dimension. During processing, they are used to build the dimension’s bitmap indexes.
Build hierarchy stores
A hierarchy store is a persistent representation of the tree structure. For each natural hierarchy in the dimension, a job is instantiated to create the hierarchy stores. For more information on hierarchy stores, see Data retrieval: dimensions.
Build bitmap indexes
To efficiently locate attribute data in the relationship store at querying time, the Storage Engine creates bitmap indexes at processing time. For attributes with a very large number of DataIDs, the bitmap indexes can take some time to process. In most scenarios, the bitmap indexes provide significant querying benefits; however, when you have high cardinality attributes, the querying benefit that the bitmap index provides may not outweigh the processing cost of creating the bitmap index. For more information on this design scenario, see Reducing attribute overhead.
Dimension-processing commands
When you need to perform a process operation on a dimension, you issue dimension processing commands. Each processing command creates one or more jobs to perform the necessary operations.
From a performance perspective, the following dimension processing commands are the most important:
- A ProcessFull command discards all storage contents of the dimension and rebuilds them. Behind the scenes, ProcessFull executes all dimension processing jobs and performs an implicit ProcessClear to discard the storage contents of all dependent partitions. This means that whenever you perform a ProcessFull of a dimension, you need to perform a ProcessFull on dependent partitions to bring the cube back online.
- ProcessData discards all storage contents of the dimension and rebuilds only the attribute and hierarchy stores. ProcessData is a component of the ProcessFull operation. ProcessData also clears partitions.
- ProcessIndexes requires that a dimension already has attribute and hierarchy stores built. ProcessIndexes preserves the data in these stores and then rebuilds the bitmap indexes. ProcessIndexes is a component of the ProcessFull operation.
- ProcessUpdate does not discard the dimension storage contents, unlike ProcessFull. Rather, it applies updates intelligently in order to preserve dependent partitions. More specifically, ProcessUpdate sends SQL queries to read the entire dimension table and then applies changes to the dimension stores. A ProcessUpdate can handle inserts, updates, and deletions depending on the type of attribute relationships (rigid vs. flexible) in the dimension. Note that ProcessUpdate will drop invalid aggregations and indexes, requiring you to take action to rebuild the aggregations in order to maintain query performance. For more information on applying ProcessUpdate, see Evaluating rigid vs. flexible aggregations.
- ProcessAdd optimizes ProcessUpdate in scenarios where you only need to insert new members. ProcessAdd does not delete or update existing members. The performance benefit of ProcessAdd is that you can use a different source table or data source view named query that restrict the rows of the source dimension table to only return the new rows. This eliminates the need to read all of the source data. In addition, ProcessAdd also retains flexible aggregations.
For a more comprehensive list of processing commands, see the Analysis Services 2005 Processing Architecture white paper located on the Microsoft Developer Network (MSDN).
Partition-processing jobs
During partition processing, source data is extracted and stored on disk using the series of jobs displayed in Figure 25.
Figure 25 Partition processing jobs
Process fact data
Fact data is processed using three concurrent threads that perform the following tasks:
- Send SQL statements to extract data from data sources.
- Look up dimension keys in dimension stores and populate the processing buffer.
- When the processing buffer is full, write out the buffer to disk.
During the processing of fact data, a potential bottleneck may be the source SQL statement. For techniques to optimize the source SQL statement, see Optimizing the source query.
Build aggregations and bitmap indexes
Aggregations are built in memory during processing. While too few aggregations may have little impact on query performance, excessive aggregations can increase processing time without much added value on query performance. As a result, care must be taken to ensure that your aggregation design supports your required processing window. For more information on deciding which aggregations to build, see Adopting an aggregation design strategy.
If aggregations do not fit in memory, chunks are written to temp files and merged at the end of the process. Bitmap indexes are built on the fact and aggregation data and written to disk on a segment by segment basis.
Partition-processing commands
When you need to perform a process operation on a partition, you issue partition processing commands. Each processing command creates one or more jobs to perform the necessary operations.
From a performance perspective, the following partition processing commands are the most important:
- ProcessFull discards the storage contents of the partition and rebuilds them. Behind the scenes, a ProcessFull executes ProcessData and ProcessIndexes jobs.
- ProcessData discards the storage contents of the object and rebuilds only the fact data.
- ProcessIndexes requires that a partition already has its data built. ProcessIndexes preserves the data and any existing aggregations and bitmap indexes and creates any missing aggregations or bitmap indexes.
- ProcessAdd internally creates a temporary partition, processes it with the target fact data, and then merges it with the existing partition. Note that ProcessAdd is the name of the XMLA command. This command is exposed in Business Intelligence Development Studio and SQL Server Management Studio as ProcessIncremental.
For a more comprehensive list of processing commands, see Analysis Services 2005 Processing Architecture white paper on MSDN.
Executing processing jobs
To manage dependencies among jobs, the Analysis Services server organizes jobs into a processing schedule. Dimensions, for example, must always be processed first, given the inherent dependency of partitions on dimensions.
Jobs without dependencies can be executed in parallel as long as there are available system resources to carry out the jobs. For example, multiple dimensions can be processed in parallel, multiple measure groups can be processed in parallel, and multiple partitions within a measure group can be processed in parallel. Analysis Services performs as many operations as it can in parallel based on available resources and the values of the following three properties: the CoordinatorExecutionMode server property, and the MaxParallel processing command, and the Threadpool\Process\MaxThreads server property. For more information on these properties, see Maximize parallelism during processing in this white paper.
In addition, before executing a processing job, Analysis Services verifies the available memory. Each job requests a specific amount of memory from the Analysis Services memory governor. If there is not enough memory available to fulfill the memory request, the memory governor can block the job. This behavior can be especially relevant in memory-constrained environments when you issue a processing request that performs multiple intensive operations such as a ProcessFull on a large partition that contains a complex aggregation design. For more information on optimizing this scenario, see Tuning memory for partition processing.
In situations where you are performing querying and processing operations at the same time, a long-running query can block a processing operation and cause it to fail. When you encounter this, the processing operation unexpectedly cancels, returning a generic error message. During the execution of a query, Analysis Services takes a read database commit lock. During processing, Analysis Services requires a write database commit lock. The ForceCommitTimeout server property identifies the amount of time a process operation waits before killing any blocking read locks. Once the timeout threshold has been reached, all transactions holding the lock will fail. The default value for this property is 30,000 milliseconds (30 seconds). Note that this property can be modified in the msmdsrv.ini configuration file; however, it is generally not recommended that you modify this setting. Rather, it is simply important to understand the impact of long-running queries on concurrent processing to help you troubleshoot any unexpected processing failures.
Refreshing dimensions efficiently
As stated previously, the performance goal of dimension processing is to refresh dimension data in an efficient manner that does not negatively impact the query performance of dependent partitions. To accomplish this, you can perform the following techniques: optimize SQL source queries, reduce attribute overhead, and prepare each dimension attribute to efficiently handle inserts, updates, deletes, as necessary.
Optimizing the source query
During processing, you can optimize the extraction of dimension source data using the following techniques:
Use OLE DB Providers over .NET Data Providers
Since the Analysis Services runtime is written in native code, OLE DB Providers offer performance benefits over .NET Data Providers. When you use .NET Data Providers, data has to be marshaled between the .NET managed memory space and the native memory space. Since OLE DB Providers are already in native code, they provide significant performance benefits over.NET Data Providers and should be used whenever possible.
Use attribute relationships to optimize attribute processing across multiple data sources
When a dimension comes from multiple data sources, using cascading attribute relationships allows the system to segment attributes during processing according to data source. If an attribute’s key, name, and attribute relationships come from the same database, the system can optimize the SQL query for that attribute by querying only one database. Without cascading attribute relationships, the SQL Server OPENROWSET function is used to merge the data streams. The OPENROWSET function provides a mechanism to access data from multiple data sources. For each attribute, a separate OPENROWSET-derived table is used. In this situation, the processing for the key attribute is extremely slow since it must access multiple OPENROWSET derived tables.
Tune the Processing Group property
When a dimension is processed, the default behavior is to issue a separate SQL statement that retrieves a distinct set of members for each attribute. This behavior is controlled by the Processing Group property, which is automatically set to ByAttribute. In most scenarios, ByAttribute provides the best processing performance; however, there are a few niche scenarios where it can be useful to change this property to ByTable. In ByTable, Analysis Services issues a single SQL statement on a per-table basis to extract a distinct set of all dimension attributes. This is potentially beneficial in scenarios where you need to process many high cardinality attributes and you are waiting a long time for the select distinct to complete for each attribute. Note that whenever ByTable is used, the server changes its processing behavior to use a multi-pass algorithm. A similar algorithm is also used for very large dimensions when the hash tables of all related attributes do not fit into memory. The algorithm can be very expensive in some scenarios because Analysis Services must read and store to disk all the data from the table in multiple data stores, and then iterate over it for each attribute. Therefore, whatever performance benefit you gain for quickly evaluating the SQL statement could be counteracted by the other processing steps. So while ByTable has the potential to be faster, it is only appropriate in scenarios where you believe that issuing one SQL statement performs significantly better than issuing multiple smaller SQL statements. In addition, note that if you use ByTable, you will see duplicate member messages when processing the dimension if you have configured the KeyDuplicate property to ReportAndContinue or ReportAndStop. In this scenario, these duplicate error messages are false positives resulting from the fact that the SQL statement is no longer returning a distinct set of members for each attribute. To better understand how these duplicates occur, consider the following example. You have a customer dimension table that has three attributes: customer key, customer name, and gender. If you set the Processing Group property to ByTable, one SQL statement is used to extract all three attributes. Given the granularly of the SQL statement, in this scenario, you will see duplicate error messages for the gender attribute if you have set the KeyDuplicate property to raise an error. Again, these error messages are likely false positives; however, you should still examine the messages to ensure that there are no unexpected duplicate values in your data.
Reducing attribute overhead
Every attribute that you include in a dimension impacts the cube size, the dimension size, the aggregation design, and processing performance. Whenever you identify an attribute that will not be used by end users, delete the attribute entirely from your dimension. Once you have removed extraneous attributes, you can apply a series of techniques to optimize the processing of remaining attributes.
Use the KeyColumns and NameColumn properties effectively
When you add a new attribute to a dimension, two properties are used to define the attribute. The KeyColumns property specifies one or more source fields that uniquely identify each instance of the attribute and the NameColumn property specifies the source field that will be displayed to end users. If you do not specify a value for the NameColumn property, it is automatically set to the value of the KeyColumns property.
Analysis Services provides the ability to source the KeyColumns and NameColumn properties from different source columns. This is useful when you have a single entity like a product that is identified by two different attributes: a surrogate key and a descriptive product name. When users want to slice data by products, they may find that the surrogate key lacks business relevance and will choose to use the product name instead.
From a processing perspective, it is a best practice to assign a numeric source field to the KeyColumns property rather than a string property. Not only can this reduce processing time, in some scenarios it can also reduce the size of the dimension. This is especially true for attributes that have a large number of members, i.e., greater than 1 million members.
Rather than using a separate attribute to store a descriptive name, you can use the NameColumn property to display a descriptive field to end users. In the product example, this means you can assign the surrogate key to the KeyColumns property and use the product name to the NameColumn property. This eliminates the need for the extraneous name attribute, making your design more efficient to query and process.
Remove bitmap indexes
During processing of the primary key attribute, bitmap indexes are created for every related attribute. Building the bitmap indexes for the primary key can take time if it has one or more related attributes with high cardinality. At querying time, the bitmap indexes for these attributes are not useful in speeding up retrieval since the Storage Engine still must sift through a large number of distinct values.
For example, the primary key of the customer dimension uniquely identifies each customer by account number; however, users also want to slice and dice data by the customer’s social security number. Each customer account number has a one-to-one relationship with a customer social security number. To avoid spending time building unnecessary bitmap indexes for the social security number attribute, it is possible to disable its bitmap indexes by setting the AttributeHierarchyOptimizedState property to Not Optimized.
Turn off the attribute hierarchy and use member properties
As an alternative to attribute hierarchies, member properties provide a different mechanism to expose dimension information. For a given attribute, member properties are automatically created for every attribute relationship. For the primary key attribute, this means that every attribute that is directly related to the primary key is available as a member property of the primary key attribute.
If you only want to access an attribute as member property, once you verify that the correct relationship is in place, you can disable the attribute’s hierarchy by setting the AttributeHierarchyEnabled property to False. From a processing perspective, disabling the attribute hierarchy can improve performance and decrease cube size because the attribute will no longer be indexed or aggregated. This can be especially useful for high cardinality attributes that have a one-to-one relationship with the primary key. High cardinality attributes such as phone numbers and addresses typically do not require slice-and-dice analysis. By disabling the hierarchies for these attributes and accessing them via member properties, you can save processing time and reduce cube size.
Deciding whether to disable the attribute’s hierarchy requires that you consider both the querying and processing impacts of using member properties. Member properties cannot be placed on a query axis in the same manner as attribute hierarchies and user hierarchies. To query a member property, you must query the properties of the attribute that contains the member property. For example, if you require the work phone number for a customer, you must query the properties of customer. As a convenience, most front-end tools easily display member properties in their user interfaces.
In general, querying member properties can be slower than querying attribute hierarchies because member properties are not indexed and do not participate in aggregations. The actual impact to query performance depends on how you are going to use the attribute. If your users want to slice and dice data by both account number and account description, from a querying perspective you may be better off having the attribute hierarchies in place and removing the bitmap indexes if processing performance is an issue. However, if you are simply displaying the work phone number on a one-off basis for a particular customer and you are spending large amounts of time in processing, disabling the attribute hierarchy and using a member property provides a good alternative.
Optimizing dimension inserts, updates, and deletes
Dimension data refreshes can be generally handled via three processing operations:
- ProcessFull—Erases and rebuilds the dimension data and structure.
- ProcessUpdate—Implements inserts, updates, and deletes based on the types of attribute relationships in the dimension. Information on the different types of attribute relationships is included later in this section.
- ProcessAdd—Provides an optimized version of ProcessUpdate to only handle data insertions.
As you plan a dimension refresh, in addition to selecting a processing operation, you must also assess how each attribute and attribute relationship is expected to change over time. More specifically, every attribute relationship has a Type property that determines how the attribute relationship should respond to data changes. The Type property can either be set to flexible or rigid where flexible is the default setting for every attribute relationship.
Use flexible relationships
Flexible relationships permit you to make a variety of data changes without requiring you to use a ProcessFull to completely rebuild the dimension every time you make a change. Remember that as soon as you implement a ProcessFull on a dimension, the cube is taken offline and you must perform a ProcessFull on every dependent partition in order to restore the ability to query the cube.
For attributes with flexible relationships, inserts, updates, and deletions can be handled by using the ProcessUpdate command. The ProcessUpdate command allows you to keep the cube “online” while the data changes are made. By default, every attribute relationship is set to flexible, although it may not always be the best choice in every design scenario. Using flexible relationships is appropriate whenever you expect an attribute to have frequent data changes and you do not want to experience the impacts of performing a ProcessFull on the dimension and cube. For example, if you expect products to frequently change from one category to another, you may decide to keep the flexible relationship between product and category so that you only need to perform a ProcessUpdate to implement the data change.
The tradeoff to using flexible relationships is their impact on data aggregations. For more information on flexible aggregations, see Evaluating rigid vs. flexible aggregations.
Note that in some processing scenarios, flexible relationships can “hide” invalid data changes in your dimension. As stated in the Identifying attribute relationships section, whenever you use attribute relationships, you must verify that each attribute’s KeyColumns property uniquely identifies each attribute member. If the KeyColumns property does not uniquely identify each member, duplicates encountered during processing are ignored by default, resulting in incorrect data rollups. More specifically, when Analysis Services encounters a duplicate member, it picks an arbitrary member depending on the processing technique that you have selected. If you perform a ProcessFull, it selects the first member it finds. If you perform a ProcessUpdate, it selects the last member it finds. To avoid this scenario, follow the best practice of always assigning the KeyColumns property with a column or combination of columns that unique identifies the attribute. If you follow this practice, you will not encounter this problem. In addition, it is a good practice to change the default error configuration to no longer ignore duplicates. To accomplish this, set the KeyDuplicate property from IgnoreError to ReportAndContinue or ReportAndStop. With this change, you can be alerted of any situation where duplicates are detected. However, this option may give you false positives in some cases (e.g., ByTable processing). For more information, see Optimizing the source query.
Use rigid relationships
For attributes with rigid relationships, inserts can be handled by using a ProcessAdd or ProcessUpdate to the dimension; however, updates and deletions require a ProcessFull of the dimension and consequently require a ProcessFull of the dependent partitions. As such, rigid relationships are most appropriate for attributes that have zero or infrequent updates or deletions. For example, in a time dimension you may assign a rigid relationship between month and quarter since the months that belong to a given quarter do not change.
If you want to assign a relationship as rigid (remember that the relationships are flexible by default), you must ensure that the source data supports the rigid relationship, i.e., no changes can be detected when you perform a ProcessAdd or ProcessUpdate. If Analysis Services detects a change, the dimension process fails and you must perform a ProcessFull. In addition, if you use rigid relationships, duplicate members are never tolerated for a given attribute, unlike in flexible relationships where an arbitrary member is selected during processing. Therefore, you must also ensure that your KeyColumns property is correctly configured.
Similar to flexible relationships, when you define rigid relationships, you must also understand their impact on data aggregations. For more information on rigid aggregations, see Evaluating rigid vs. flexible aggregations.
Refreshing partitions efficiently
The performance goal of partition processing is to refresh fact data and aggregations in an efficient manner that satisfies your overall data refresh requirements. To help you refresh your partitions, the following techniques are discussed in this topic: optimizing SQL source queries, using multiple partitions, effectively handling data inserts, updates, and deletes, and evaluating the usage of rigid vs. flexible aggregations.
Optimizing the source query
To enhance partition processing, there are two general best practices that you can apply for optimizing the source query that extracts fact data from the source database.
Use OLE DB Providers over .NET Data Providers
This is the same recommendation provided for the dimension processing. Since the Analysis Services runtime is written in native code, OLE DB Providers offer performance benefits over.NET Data Providers. When you use .NET Data Providers, data has to be marshaled between the .NET managed memory space and the native memory space. Since OLE DB Providers are already in native code, they provide significant performance benefits over the .NET Data Providers.
Use query bindings for partitions
A partition can be bound to either a source table or a source query. When you bind to a source query, as long as you return the correct number of columns expected in the partition, you can create a wide range of SQL statements to extract source data. Using source query bindings provides greater flexibility than using a named query in the data source view. For example, using query binding, you can point to a different data source using four-part naming and perform additional joins as necessary.
Using partitions to enhance processing performance
In the same manner that using multiple partitions can reduce the amount of data that needs to be scanned during data retrieval (as discussed in How partitions are used in querying), using multiple partitions can enhance processing performance by providing you with the ability to process smaller data components of a measure group in parallel.
Being able to process multiple partitions in parallel is useful in a variety of scenarios; however, there are a few guidelines that you must follow. When you initially create a cube, you must perform a ProcessFull on all measure groups in that cube.
If you process partitions from different client sessions, keep in mind that whenever you process a measure group that has no processed partitions, Analysis Services must initialize the cube structure for that measure group. To do this, it takes an exclusive lock that prevents parallel processing of partitions. If this is the case, you should ensure that you have at least one processed partition per measure group before you begin parallel operations. If you do not have a processed partition, you can perform a ProcessStructure on the cube to build its initial structure and then proceed to process measure group partitions in parallel. In the majority of scenarios, you will not encounter this limitation if you process partitions in the same client session and use the MaxParallel XMLA element to control the level of parallelism. For more information on using MaxParallel, see Maximize parallelism during processing.
After initially loading your cube, multiple partitions are useful when you need to perform targeted data refreshes. Consider the following example. If you have a sales cube with a single partition, every time that you add new data such as a new day’s worth of sales, you must not only refresh the fact data, but you must also refresh the aggregations to reflect the new data totals. This can be costly and time consuming depending on how much data you have in the partition, the aggregation design for the cube, and the type of processing that you perform.
With multiple partitions, you can isolate your data refresh operations to specific partitions. For example, when you need to insert new fact data, an effective technique involves creating a new partition to contain the new data and then performing a ProcessFull on the new partition. Using this technique, you can avoid impacting the other existing partitions. Note that it is possible to use XMLA scripts to automate the creation of a new partition during the refresh of your relational data warehouse.
Optimizing data inserts, updates, and deletes
This section provides guidance on how to efficiently refresh partition data to handle inserts, updates, and deletes.
Inserts
If you have a browseable cube and you need to add new data to an existing measure group partition, you can apply one of the following techniques:
- ProcessFull—Perform a ProcessFull for the existing partition. During the ProcessFull operation, the cube remains available for browsing with the existing data while a separate set of data files are created to contain the new data. When the processing is complete, the new partition data is available for browsing. Note that a ProcessFull is technically not necessary given that you are only doing inserts. To optimize processing for insert operations, you can use a ProcessAdd.
- ProcessAdd—Use this operation to append data to the existing partition files. If you frequently perform a ProcessAdd, it is advised that you periodically perform a ProcessFull in order to rebuild and re-compress the partition data files. ProcessAdd internally creates a temp partition and merges it. This results in data fragmentation over time and the need to periodically perform a ProcessFull.
If your measure group contains multiple partitions, as described in the previous section, a more effective approach is to create a new partition that contains the new data and then perform a ProcessFull on that partition. This technique allows you to add new data without impacting the existing partitions. When the new partition has completed processing, it is available for querying.
Updates
When you need to perform data updates, you can perform a ProcessFull. Of course it is useful if you can target the updates to a specific partition so you only have to process a single partition. Rather than directly updating fact data, a better practice is to use a “journaling” mechanism to implement data changes. In this scenario, you turn an update into an insertion that corrects that existing data. With this approach, you can simply continue to add new data to the partition by using a ProcessAdd. You can also have an audit trail of the changes that you have made.
Deletes
For deletions, multiple partitions provide a great mechanism for you to roll out expired data. Consider the following example. You currently have 13 months of data in a measure group, one month per partition. You want to roll out the oldest month from the cube. To do this, you can simply delete the partition without affecting any of the other partitions. If there are any old dimension members that only appeared in the expired month, you can remove these using a ProcessUpdate of the dimension (as long it contains flexible relationships). In order to delete members from the key/granularity attribute of a dimension, you must set the dimension’s UnknownMember property to Hidden or Visible. This is because the server does not know if there is a fact record assigned to the deleted member. With this property set appropriately, it will associate it to the unknown member at query time.
Evaluating rigid vs. flexible aggregations
Flexible and rigid attribute relationships not only impact how you process dimensions, but they also impact how aggregations are refreshed in a partition. Aggregations can either be categorized as rigid or flexible depending on the relationships of the attributes participating in the aggregation. For more information on the impact of rigid and flexible relationships, see Optimizing dimension inserts, updates, and deletes.
Rigid aggregations
An aggregation is rigid when all of the attributes participating in the aggregation have rigid direct or indirect relationships to the granularity attribute of a measure group. For all attributes in the aggregation, a check is performed to verify that all relationships are rigid. If any are flexible, the aggregation is flexible.
Flexible aggregations
An aggregation is flexible when one or more of the attributes participating in the aggregation have flexible direct or indirect relationships to the key attribute.
If you perform a ProcessUpdate on a dimension participating in flexible aggregations, whenever deletions or updates are detected for a given attribute, the aggregations for that attribute as well as any related attributes in the attribute chain are automatically dropped. The aggregations are not automatically recreated unless you perform one of the following tasks:
- Perform a ProcessFull on the cube, measure group, or partition. This is the standard ProcessFull operation that drops and re-creates the fact data and all aggregations in the partition.
- Perform a ProcessIndexes on the
cube, measure group, or partition.
By performing ProcessIndexes, you will only build whatever aggregations or indexes that need to be re-built.
- Configure Lazy Processing for the cube, measure group, or partition. If you configure Lazy Processing, the dropped aggregations are recalculated as a background task. While the flexible aggregations are being recalculated, users can continue to query the cube (without the benefit of the flexible aggregations). While the flexible aggregations are being recalculated, queries that would benefit from the flexible aggregations run slower because Analysis Services resolves these queries by scanning the fact data and then summarizing the data at query time. As the flexible aggregations are recalculated, they become available incrementally on a partition-by-partition basis. For a given cube, Lazy Processing is not enabled by default. You can configure it for a cube, measure group, or partition by changing the ProcessingMode property from Regular to LazyAggregations. To manage Lazy Processing, there are a series of server properties such as the LazyProcessing \ MaxObjectsInParallel setting, which controls the number of objects that can be lazy processed at a given time. By default it is set to 2. By increasing this number, you increase the number of objects processed in parallel; however, this also impacts query performance and should therefore be handled with care.
- Process affected objects. When you perform a ProcessUpdate on a dimension, you can choose whether or not to Process Affected Objects. If you select this option, you can trigger the update of dependent partitions within the same operation.
Note that if you do not follow one of the above techniques, and you perform a ProcessUpdate of a dimension that results in a deletion or update, the flexible aggregations for that attribute and all related attributes in the attribute chain are automatically deleted and not re-created, resulting in poor query performance. This is especially important to note because by default every aggregation is flexible since every attribute relationship type is set to Flexible.
As a result, great care must be taken to ensure that your refresh strategy configures the appropriate attribute relationships for your data changes and effectively rebuilds any flexible aggregations on an ongoing basis.
Optimizing Special Design Scenarios
Throughout this whitepaper, specific techniques and best practices are identified for improving the processing and query performance of Analysis Services OLAP databases. In addition to these techniques, there are specific design scenarios that require special performance tuning practices. Following is an overview of the design scenarios that are addressed in this section:
Special aggregate functions – Special aggregate functions allow you to implement distinct count and semiadditive data summarizations. Given the unique nature of these aggregate functions, special performance tuning techniques are required to ensure that they are implemented in the most efficient manner.
Parent-child hierarchies – Parent-child hierarchies have a different aggregation scheme than attribute and user hierarchies, requiring that you consider their impact on query performance in large-scale dimensions.
Complex Dimension Relationships – Complex dimension relationships include many-to-many relationships and reference relationships. While these relationships allow you to handle a variety of schema designs, complex dimension relationships also require you to assess how the schema complexity is going to impact processing and/or query performance.
Near real-time data refreshes – In some design scenarios, “near real-time” data refreshes are a necessary requirement. Whenever you implement a “near real-time” solution requiring low levels of data latency, you must consider how you are going to balance the required latency with querying and processing performance.
Special aggregate functions
Aggregate functions are the most common mechanism to summarize data. Aggregate functions are uniformly applied across all attributes in a dimension and can be used for additive, semiadditive, and nonadditive measures. Aggregate functions can be categorized into two general groups: traditional aggregate functions and special aggregate functions.
- Traditional aggregate functions consist of a group of functions that follow the general performance tuning recommendations described in other sections of this white paper. Traditional aggregate functions include Sum, Count, Min, and Max.
- Special aggregate functions require unique performance-tuning techniques. They include DistinctCount and a collection of semiadditive aggregate functions. The semiadditive functions include: FirstChild, LastChild, FirstNonEmpty, LastNonEmpty, ByAccount, and AverageOfChildren.
Optimizing distinct count
DistinctCount is a nonadditive aggregate function that counts the unique instances of an entity in a measure group. While distinct count is a very powerful analytical tool, it can have significant impact on processing and querying performance because of its explosive impact on aggregation size. When you use a distinct count aggregate function, it increases the size of an aggregation by the number of unique instances that are distinctly counted.
To better understand how distinct count impacts aggregation size, consider the following example. You have a measure group partition with an aggregation that summarizes sales amount by product category and year. You have ten product categories with sales for ten years, producing a total of 100 values in the aggregation. When you add a distinct count of customers to the measure group, the aggregation for the partition changes to include the customer key of each customer who has sales for a specific product category and year. If there are 1,000 customers, the number of potential values in the aggregation increases from 100 to 100,000 values, given that every customer has sales for every product category in every year. (Note that the actual number of values would be less than 100,000 due to natural data sparsity. At any rate, the value is likely to be a number much greater than 100.) While this additional level of detail is necessary to efficiently calculate the distinct count of customers, it introduces significant performance overhead when users request summaries of sales amount by product category and year.
With the explosive impact of distinct counts on aggregations, it is a best practice to separate each distinct count measure into its own measure group with the same dimensionality as the initial measure group. Using this technique, you can isolate the distinct count aggregations and maintain a separate aggregation design for non-distinct count measures.
Note that when you use Business Intelligence Development Studio to create a new measure, if you specify the distinct count aggregate function at the time of the measure creation, the Analysis Services Cube Designer automatically creates a separate measure group for the distinct count measure. However, if you change the aggregate function for an existing measure to distinct count, you must manually reorganize the distinct count measure into its own measure group.
When you are distinctly counting large amount of data, you may find that the aggregations for the distinct count measure group are not providing significant value, since the fact data must typically be queried to calculate the distinct counts. For a distinct count measure group, you should consider partitioning the measure group using data ranges of the distinct count field. For example, if you are performing a distinct count of customers using customer ID, consider partitioning the distinct count measure group by customer ID ranges. In this scenario, partition 1 may contain customer IDs between 1 and 1000. Partition 2 may contain customer IDs between 1001 and 2000. Partition 3 may contain customer IDs between 2001 and 3000, etc. This partitioning scheme improves query parallelism since the server does not have to coordinate data across partitions to satisfy the query.
For larger partitions, to further enhance performance, it may be advantageous to consider an enhanced partitioning strategy where you partition the distinct count measure group by both the distinct count field as well as your normal partitioning attribute, i.e., year, month, etc. As you consider your partitioning strategy for distinct count, keep in mind that when you partition by multiple dimensions, you may quickly find out that you have too many partitions. With too many partitions, in some scenarios you can actually negatively impact query performance if Analysis Services needs to scan and piece together data from multiple partitions at query time. For example, if you partition by sales territory and day, when users want the distinct count of customers by sales territory by year, all of the daily partitions in a specific year must be accessed and assimilated to return the correct value. While this will naturally happen in parallel, it can potentially result in additional querying overhead. To help you determine the size of and scope of your partitions, see the general sizing guidance in the Designing partitions section.
From a processing perspective, whenever you process a partition that contains a distinct count, you will notice an increase in processing time over your other partitions of the same dimensionality. It takes longer to process because of the increased size of the fact data and aggregations. The larger the amount of data that requires processing, the longer it takes to process, and the greater potential that Analysis Services may encounter memory constraints and will need to use temporary files to complete the processing of the aggregation. You must therefore assess whether your aggregation design is providing you with the most beneficial aggregations. To help you determine this, you can use the Usage-Based Optimization Wizard to customize your aggregation design to benefit your query workload. If you want further control over the aggregation design, you may want to consider creating custom aggregations by using the Aggregation Utility described in Appendix C. In addition, you must ensure that the system has enough resources to process the aggregations. For more information on this topic, see Tuning Server Resources.
The other reason that processing time may be slower is due to the fact that an ORDER BY clause is automatically added to the partition’s source SQL statement. To optimize the performance of the ORDER BY in the source SQL statement, you can place a clustered index on the source table column that is being distinctly counted. Keep in mind that this is only applicable in the scenario where you have one distinct count per fact table. If you have multiple distinct counts off of a single fact table, you need to evaluate which distinct count will benefit most from the clustered index. For example, you may choose to apply the clustered index to the most granular distinct count field.
Optimizing semiadditive measures
Semiadditive aggregate functions include ByAccount, AverageOfChildren, FirstChild, LastChild, FirstNonEmpty, and LastNonEmpty. To return the correct data values, semiadditive functions must always retrieve data that includes the granularity attribute of the time dimension. Since semiadditive functions require more detailed data and additional server resources, to enhance performance, semiadditive measures should not be used in a cube that contains ROLAP dimensions or linked dimensions. ROLAP and linked dimensions also require additional querying overhead and server resources. Therefore, the combination of semiadditive measures with ROLAP and/or linked dimensions can result in poor query performance and should be avoided where possible.
Aggregations containing the granularity attribute of the time dimension are extremely beneficial for efficiently satisfying query requests for semiadditive measures. Aggregations containing other time attributes are never used to fulfill the request of a semiadditive measure.
To further explain how aggregations are used to satisfy query requests for semiadditive measures, consider the following example. In an inventory application, when you request a product’s quantity on hand for a given month, the inventory balance for the month is actually the inventory balance for the final day in that month. To return this value, the Storage Engine must access partition data at the day level. If there is an appropriate aggregation that includes the day attribute, the Storage Engine will attempt to use that aggregation to satisfy the query. Otherwise the query must be satisfied by the partition fact data. Aggregations at the month and year cannot be used.
Note that if your cube contains only semiadditive measures, you will never receive performance benefits from aggregations created for nongranularity time attributes. In this scenario, you can influence the aggregation designer to create aggregations only for the granularity attribute of the time dimension (and the All attribute) by setting the Aggregation Usage to None for the nongranularity attributes of the time dimension. Keep in mind that the Aggregation Usage setting automatically applies to all measure groups in the cube, so if the cube contains only semiadditive measures, such as in inventory applications, the Aggregation Usage setting can be uniformly applied across all measure groups.
If you have a mixed combination of semiadditive measures and other measures across measure groups, you can adopt the following technique to apply unique aggregation usage settings to specific measure groups. First, adjust the Aggregation Usage settings for a dimension so that they fit the needs of a particular measure group and then design aggregations for that measure group only. Next, change the Aggregation Usage settings to fit the needs of the next measure group and then design aggregations for that measure group only. Using this approach, you can design aggregations measure group-by-measure group, and even partition-by-partition if desired.
In addition to this technique, you can also optimize the aggregation design using the Usage-Based Optimization Wizard to create only those aggregations that provide the most value for your query patterns. If you want further control over the aggregation design, you may want to consider creating custom aggregations using the Aggregation Utility described in Appendix C.
Parent-child hierarchies
Parent-child hierarchies are hierarchies with a variable number of levels, as determined by a recursive relationship between a child attribute and a parent attribute. Parent-child hierarchies are typically used to represent a financial chart of accounts or an organizational chart. In parent-child hierarchies, aggregations are created only for the key attribute and the top attribute, i.e., the All attribute unless it is disabled. As such, refrain from using parent-child hierarchies that contain large numbers of members at intermediate levels of the hierarchy. Additionally, you should limit the number of parent-child hierarchies in your cube.
If you are in a design scenario with a large parent-child hierarchy (greater than 250,000 members), you may want to consider altering the source schema to re-organize part or all of the hierarchy into a user hierarchy with a fixed number of levels. Once the data has been reorganized into the user hierarchy, you can use the Hide Member If property of each level to hide the redundant or missing members.
Complex dimension relationships
The flexibility of Analysis Services enables you to build cubes from a variety of source schemas. For more complicated schemas, Analysis Services supplies many-to-many relationships and reference relationships to help you model complex associations between your dimension tables and fact tables. While these relationships provide a great deal of flexibility, to use them effectively, you must evaluate their impact on processing and query performance.
Many-to-many relationships
In Analysis Services, many-to-many relationships allow you to easily model complex source schemas. To use many-to-many relationships effectively, you must be familiar with the business scenarios where these relationships are relevant.
Background information on many-to-many relationships
In typical design scenarios, fact tables are joined to dimension tables via many-to-one relationships. More specifically, each fact table record can join to only one dimension table record and each dimension table record can join to multiple fact table records. Using this many-to-one design, you can easily submit queries that aggregate data by any dimension attribute.
Many-to-many design scenarios occur when a fact table record can potentially join to multiple dimension table records. When this situation occurs, it is more difficult to correctly query and aggregate data since the dimension contains multiple instances of a dimension entity and the fact table cannot distinguish among the instances.
To better understand how many-to-many relationships impact data analysis, consider the following example. You have a reseller dimension where the primary key is the individual reseller. To enhance your analysis, you want to add the consumer specialty attribute to the reseller dimension. Upon examining data, you notice that each reseller can have multiple consumer specialties. For example, A Bike Store has two consumer specialties: Bike Enthusiast and Professional Bike. Your sales fact table, however, only tracks sales by reseller, not by reseller and consumer specialty. In other words, the sales data does not distinguish between A Bike Shop with a Bike Enthusiast specialty and A Bike Shop with a Professional Bike specialty. In the absence of some kind of weighting factor to allocate the sales by consumer specialty, it is a common practice to repeat the sales values for each reseller/consumer specialty combination. This approach works just fine when you are viewing data by consumer specialty and reseller; however, it poses a challenge when you want to examine data totals as well as when you want to analyze data by other attributes.
Continuing with the reseller example, if you add the new consumer specialty attribute to the reseller dimension table, whenever the fact table is joined to the dimension table via the individual reseller, the number of records in the result set is multiplied by the number of combinations of reseller and consumer specialty. When the data from this result set is aggregated, it will be inflated. In the example of A Bike Shop, sales data from the fact table will be double-counted regardless of which reseller attribute you group by. This double-counting occurs because A Bike Shop appears twice in the table with two consumer specialties. This data repeating is okay when you are viewing the breakdown of sales by consumer specialty and reseller; however, any sales totals or queries that do not include consumer specialty will be incorrectly inflated.
To avoid incorrectly inflating your data, many-to-many relationships are typically modeled in the source schema using multiple tables as displayed in Figure 26.
- A main dimension table contains a unique list of primary key values and other attributes that have a one-to-one relationship to the primary key. To enable the dimension table to maintain a one-to-many relationship with the fact table, the multivalued attribute is not included in this dimension. In the reseller example displayed in Figure 26, Dim Reseller is the main dimension table, storing one record per reseller. The multivalued attribute, consumer specialty, is not included in this table.
- A second dimension table contains a unique list of values for the multivalued attribute. In the reseller example, the Dim Consumer Specialty dimension table stores the distinct list of consumer specialties.
- An intermediate fact table maps the relationship between the two dimension tables. In the reseller example, Fact Reseller Specialty is an intermediate fact table that tracks the consumer specialties of each reseller.
- The data fact table stores a foreign key reference to the primary key of the main dimension table. In the reseller example, the Fact Sales table stores the numeric sales data and has a many-to-one relationship with Dim Reseller via the Reseller Key.
Figure 26 Many-to-many relationship
Using this design, you have maintained the many-to-one relationship between Fact Sales and Dim Reseller. This means that if you ignore Dim Consumer Specialty and Fact Reseller Specialty, you can easily query and aggregate data from Fact Sales by any attribute in the Dim Reseller table without incorrectly inflating values. However this design does not fully solve the problem, since it is still tricky to analyze sales by an attribute in Dim Consumer Specialty. Remember that you still do not have sales broken down by consumer specialty; i.e., sales is only stored by reseller and repeats for each reseller / consumer specialty combination. For queries that summarize sales by consumer specialty, the data totals are still inflated unless you can apply a distinct sum.
To help you accomplish this distinct sum, Analysis Services provides built-in support for many-to-many relationships. Once a many-to-many relationship is defined, Analysis Services can apply distinct sums to correctly aggregate data where necessary. To obtain this benefit in the reseller example, first create the Sales measure group that includes the Dim Reseller dimension and sales measures from the Fact Sales table. Next, you can use a many-to-many relationship to relate the Sales measure group to the Consumer Specialty many-to-many dimension. To set up this relationship, you must identify an intermediate measure group that can be used to map Sales data to Consumer Specialty. In this scenario, the intermediate measure group is Reseller Specialty, sourced from the Fact Reseller Specialty fact table.
Performance considerations
During processing, the data and intermediate measure groups are processed independently. Fact data and aggregations for the data measure group do not include any attributes from the many-to-many dimension. When you query the data measure group by the many-to-many dimension, a run-time “join” is performed between the two measure groups using the granularity attributes of each dimension that the measure groups have in common. In the example in Figure 26, when users want to query Sales data by Consumer Specialty, a run-time join is performed between the Sales measure group and Reseller Specialty measure group using the Reseller Key of the Reseller dimension. From a performance perspective, the run-time join has the greatest impact on query performance. More specifically, if the intermediate measure group is larger than the data measure group or if the many-to-many dimension is generally large (at least one million members), you can experience query performance issues due to the amount of data that needs to be joined at run time. To optimize the run-time join, review the aggregation design for the intermediate measure group to verify that aggregations include attributes from the many-to-many dimension. In the example in Figure 26, aggregations for the intermediate measure group should include attributes from the Consumer Specialty dimension such as the description attribute. While many-to-many relationships are very powerful, to avoid query performance issues, in general you should limit your use of many-to-many relationships to smaller intermediate measure groups and dimensions.
Reference relationships
In traditional dimension design scenarios, all dimension tables join directly to the fact table by means of their primary keys. In snowflake dimension designs, multiple dimension tables are chained together, with the chained dimensions joining indirectly to the fact table by means of a key in another dimension table. These chained dimensions are often called snowflake dimension tables. Figure 27 displays an example of snowflake dimension tables. Each table in the snowflake is linked to a subsequent table via a foreign key reference.
Figure 27 Snowflake dimension tables
In Figure 27, the Dim Reseller table has a snowflake relationship to the Dim Geography table. In addition, the Dim Customer table has a snowflake relationship to the Dim Geography table. From a relational point of view, if you want to analyze customer sales by geography, you must join Dim Geography to Fact Customer Sales via Dim Customer. If you want to analyze reseller sales by geography, you must join Dim Geography to Fact Reseller Sales via Dim Reseller.
Within Analysis Services, dimensions are “joined” to measure groups by specifying the dimension’s relationship type. Most dimensions have regular relationships where a dimension table is joined directly to the fact table. However, for snowflake dimension table scenarios, such as the one depicted in Figure 27, there are two general design techniques that you can adopt as described in this section.
Option 1 – Combine attributes
For each dimension entity that joins to the fact table, create a single OLAP dimension that combines attributes from all of the snowflake dimension tables, and then join each dimension to measure group using a regular relationship type. If you have multiple dimension entities that reference the same snowflake tables, attributes from the shared snowflake tables are repeated across the OLAP dimensions.
To apply this technique to the Figure 27 example, create two OLAP dimensions: 1) a Reseller dimension that contains attributes from both the Dim Reseller and Dim Geography tables, and 2) a Customer dimension that contains attributes from Dim Customer and Dim Geography. Note that attributes from Dim Geography are repeated across both the Reseller and Customer dimensions.
For the Reseller Sales measure group, use a Regular relationship for the Reseller dimension. For the Customer Sales measure group, use a regular relationship Customer dimension. Remember that the relationship between a dimension and a measure group defines how the dimension data is to be “joined” to the fact data. A regular relationship means that you have defined a direct relationship between one or more dimension columns and one or more measure group columns.
With this design, for each OLAP dimension, all of the snowflake dimension tables are joined together at processing time and the OLAP dimension is materialized on disk. As with any other processing operation, you can control whether the processing should remove missing keys or use the unknown member for any records that do join across all tables.
From a performance perspective, the benefit of this approach is the ability to create natural hierarchies and use aggregations. Since each dimension has a regular relationship to the measure group, to enhance query performance, aggregations can be designed for attributes in each dimension, given the proper configuration of attribute relationships. In addition, during querying, you can take advantage of Autoexists optimizations that naturally occur between attributes within a dimension. For more information on Autoexists, see Removing empty tuples.
If you use this approach, you must also consider the impact of increasing the number of attributes that the aggregation design algorithm must consider. By repeating attributes across multiple dimensions, you are creating more work for the aggregation design algorithm which could negatively impact processing times.
Option 2 – Use a reference relationship
An alternative design approach to combining attributes involves reference relationships. Reference relationships allow you to indirectly relate OLAP dimensions to a measure group using an intermediate dimension. The intermediate dimension creates a “join” path that the measure group can use to relate its data to each reference dimension.
To apply this technique to the example in Figure 27, create three separate OLAP dimensions for customer, reseller, and geography. The following describes how these dimensions can be related to each measure group (Reseller Sales and Customer Sales):
- The Customer Sales measure group contains a regular relationship to the Customer dimension and contains a reference relationship to the Geography dimension. The reference relationship uses Customer as an intermediate dimension to assign sales to specific geographies.
- The Reseller Sales measure group contains a regular relationship to the Reseller dimension and contains a reference relationship to the Geography dimension. The reference relationship uses Reseller as an intermediate dimension to assign sales to specific geographies.
To use this technique effectively, you must consider the impacts of reference relationships on processing and query performance. During processing, each dimension is processed independently. No attributes from the reference dimension are automatically considered for aggregation. During querying, measure group data is joined to the reference dimension as necessary by means of the intermediate dimension. For example, if you query customer sales data by geography, a run-time join must occur from the Customer Sales measure group to Geography via the Customer dimension. This process can be somewhat slow for large dimensions. In addition, any missing attribute members that are encountered during querying are automatically assigned to the unknown member in order to preserve data totals.
To improve the query performance of reference relationships, you can choose to materialize them. Note that by default, reference relationships are not materialized. When a reference relationship is materialized, the joining across dimensions is performed during processing as opposed to querying. In addition, the attributes in the materialized reference dimensions follow the aggregation rules of standard dimensions. For more information on these rules, see The aggregation usage rules. Since the join is performed during processing and aggregations are possible, materialized reference relationships can significantly improve query performance when compared to unmaterialized relationships.
Some additional considerations apply to materialized reference relationships. During processing, the reference dimension is processed independently. At this time, if any row in the measure group does not join to the reference dimension, the record is removed from the partition. Note that this is different behavior than the unmaterialized reference relationship where missing members are assigned to the unknown member.
To better understand how missing members are handled for materialized relationships, consider the following example. If you have a sales order in the Customer Sales fact table that maps to a specific customer but that customer has a missing geography, the record cannot join to the Geography table and is rejected from the partition. Therefore, if you have referential integrity issues in your source data, materializing the reference relationship can result in missing data from the partition for those fact records that do not join to the reference dimension. To counteract this behavior and handle missing values, you can create your own unknown dimension record in the reference dimension table and then assign that value to all records missing reference values during your extraction, transformation, and loading (ETL) processes. With the unknown record in place for missing values, at processing time, all customer records can successfully join to the reference dimension.
Option Comparison – Combining attributes vs. using reference relationships
When you compare these two design alternatives, it is important to assess the overall impacts on processing and query performance. When you combine attributes, you can benefit from creating natural hierarchies and using aggregations to improve query performance. When you use reference relationships, a reference dimension can only participate in aggregations if it is materialized. These aggregations will not take into account any hierarchies across dimensions, since the reference dimension is analyzed separately from the other dimensions. In light of this information, the following guidelines can help you decide which approach to adopt:
- If your dimension is frequently queried and can benefit from natural hierarchies and aggregations, you should combine attributes from snowflake dimension tables into your normal dimension design.
- If the dimension is not frequently queried and is only used for one-off analysis, you can use unmaterialized reference relationships to expose the dimension for browsing without the overhead of creating aggregations for dimension attributes that are not commonly queried. If the intermediate dimensions are large, to optimize the query performance you can materialize the reference relationship.
As an additional design consideration, note that the example in Figure 27 includes snowflake tables with two fact tables / measure groups. When you have snowflake tables that join to a single fact table/ measure group, as depicted in Figure 28, the only available design option is to combine attributes.

Figure 28 One measure group
Reference relationships are not applicable to this design scenario because Analysis Services only allows one reference relationship per dimension per measure group. In the example in Figure 28, this means that when you define Dim Geography as a reference dimension to Reseller Sales, you must either select Dim Reseller or Dim Employee as the intermediate dimension. This either/or selection is not likely going to satisfy your business requirements. As a result, in this scenario, you can use design option 1, combining attributes, to model the snowflake dimension tables.
Near real-time data refreshes
Whenever you have an application that requires a low level of latency, such as in near real-time data refreshes, you must consider a special set of performance tuning techniques that can help you balance low levels of data latency with optimal processing and query performance.
Generally speaking, low levels of data latency include hourly, minute, and second refresh intervals. When you need to access refreshed data on an hourly basis, for example, your first instinct may be to process all of your dimensions and measure groups every hour. However, if it takes 30 minutes to process all database objects, to meet the hourly requirement, you would need to reprocess every 30 minutes. To further complicate this, you would also need to assess the performance impact of any concurrent querying operations that are competing for server resources.
Instead of processing all measure groups and dimensions to meet a low latency requirement, to improve performance and enhance manageability, you can use partitions to isolate the low latency data from the rest of the data. Typically this means that you create one or more near real-time partitions that are constantly being updated with refreshed data. Isolating the low latency data follows normal best practices for partitioning so that you can process and update the near real-time partitions without impacting the other partitions. Using this solution, you can also reduce the amount of data that needs to be processed in near real-time.
With partitions in place, the next step is to decide on how you are going to refresh the data in your near real-time partition(s). Remember that partitions require you to process them in order to refresh the data. Depending on the size of your near real-time partition(s) and the required frequency of the data updates, you can either schedule the refresh of a partition on a periodic basis or you can enable Analysis Services to manage the refresh of a partition using proactive caching.
Proactive caching is a feature in Analysis Services that transparently synchronizes and maintains a partition or dimension much like a cache. A proactive caching partition or dimension is commonly referred to as a cache, even though it is still considered to be a partition or dimension. Using proactive caching, you can enable Analysis Services to automatically detect a data change in the source data, to incrementally update or rebuild the cache with the refreshed data, and to expose the refreshed data to end users.
Even though proactive caching automates much of the refresh work for you, from a performance perspective, you must still consider the typical parameters that impact processing performance such as the frequency of source system updates, the amount of time it takes to update or rebuild the cache, and the level of data latency that end users are willing to accept.
From a performance perspective, there are three groups of settings that impact query responsiveness and processing performance for proactive caching: notification settings, refresh settings, and availability settings.
Notification settings
Notification settings impact how Analysis Services detects data changes in the source system. To satisfy the needs of different data architectures, Analysis Services provides a few mechanisms that you can use to notify Analysis Services of data changes. From a performance perspective, the Scheduled polling mechanism provides the most flexibility by allowing you to either rebuild or incrementally update the cache. Incremental updates improve proactive caching performance by reducing the amount of data that needs to be processed. For proactive caching partitions, incremental updates use a ProcessAdd to append new data to the cache. For proactive caching dimensions, a ProcessUpdate is performed. If you use Scheduled polling without incremental updates, the cache is always completely rebuilt.
Refresh settings
Refresh settings impact when Analysis Services rebuilds or updates the cache. The two most important refresh settings are Silence Interval and Silence Override Interval.
- Silence Interval defines how long Analysis Services waits from the point at which it detects a change to when it begins refreshing the cache. Since Analysis Services does not officially know when source data changes are finished, the goal is for Analysis Services to refresh the cache when there is a lull in the propagation of source data changes. The lull is defined by a period of silence or no activity that must expire before Analysis Services refreshes the cache. Consider the example where the Silence Interval is set to ten seconds and your cache is configured to be fully rebuilt during refresh. In this scenario, once Analysis Services detects a data change, a time counter starts. If ten seconds pass and no additional changes are detected, Analysis Services rebuilds the cache. If Analysis Services detects additional changes during that time period, the time counter resets each time a change is detected.
- Silence Override Interval determines how long Analysis Services waits before performing a forced refresh of the cache. Silence Override Interval is useful when your source database is updated frequently and the Silence Interval threshold cannot be reached, since the time counter is continuously reset. In this scenario, you can use the Silence Override Interval to force a refresh of the cache after a certain period of time, such as five minutes or ten minutes. For example, if you set the Silence Override Interval to ten minutes, every ten minutes Analysis Services refreshes the cache only if a change was detected.
Availability settings
Availability settings allow you to control how data is exposed to end users during cache refresh. If
your cache takes several minutes to update or rebuild, you may want to consider configuring the proactive caching settings to allow users to see an older cache until the refreshed cache is ready. For example, if you configure a partition to use Automatic MOLAP settings (Silence Interval = 10 seconds and Silence Override Interval = 10 minutes), during cache refresh, users query the old cache until the new cache is ready. If the cache takes five hours to rebuild, users must wait five hours for cache rebuild to complete. If you always want users to view refreshed data, enable the Bring Online Immediately setting. With Bring Online Immediately enabled, during cache refresh all queries are directed to the relational source database to retrieve the latest data for end users. While this provides users with refreshed data, it can also result in reduced query performance given that Analysis Services needs to redirect queries to the relational source database. If you want finer grained control over users viewing refreshed data, you can use the Latency setting to define a threshold that controls when queries are redirected to the source database during a cache refresh. For example, if you set Latency to four hours and the cache requires five hours to rebuild, for four hours, the queries will be satisfied by the older cache. After four hours, queries are redirected to the source database until the cache has completed its refresh.
Figure 29 illustrates how the proactive caching settings impact queries during cache rebuilding.
Figure 29 Proactive caching example
Generally speaking, to maximize query performance, it is a good practice to increase Latency where possible so that queries can continue to execute against the existing cache while data is read and processed into a new cache whenever the silence interval or silence override interval is reached. If you set the Latency too low, query performance may suffer as queries are continuously redirected to the relational source. Switching back and forth between the partition and the relational source can provide very unpredictable query response times for users. If you expect queries to constantly be redirected to the source database, to optimize query performance, you must ensure that Analysis Services understands the partition’s data slice. Setting a partition’s data slice is not necessary for traditional partitions. However, the data slice must be manually set for proactive caching partitions, as well as any ROLAP partition. In light of the potential redirection of queries to the relational source, proactive caching is generally not recommended on cubes that are based on multiple data sources.
If you enable proactive caching for your dimensions, to optimize processing, pay special attention to the Latency setting for each dimension and the overall impact of redirecting queries to the source database. When a dimension switches from the dimension cache to the relational database, all partitions that use the dimension need to be fully reprocessed. Therefore, where possible, it is a good idea to ensure that the Latency setting allows you to query the old cache until the new cache is rebuilt.
Tuning Server Resources
Query responsiveness and efficient processing require effective usage of memory, CPU, and disk resources. To control the usage of these resources, Analysis Services 2005 introduces a new memory architecture and threading model that use innovative techniques to manage resource requests during querying and processing operations.
To optimize resource usage across various server environments and workloads, for every Analysis Services instance, Analysis Services exposes a collection of server configuration properties. To provide ease-of-configuration, during installation of Analysis Services 2005, many of these server properties are dynamically assigned based on the server’s physical memory and number of logical processors. Given their dynamic nature, the default values for many of the server properties are sufficient for most Analysis Services deployments. This is different behavior than previous versions of Analysis Services where server properties were typically assigned static values that required direct modification. While the Analysis Services 2005 default values apply to most deployments, there are some implementation scenarios where you may be required to fine tune server properties in order to optimize resource utilization.
Regardless of whether you need to alter the server configuration properties, it is always a best practice to acquaint yourself with how Analysis Services uses memory, CPU, and disk resources so you can evaluate how resources are being utilized in your server environment.
For each resource, this section presents two topics: 1) a topic that describes how Analysis Services uses system resources during querying and processing, and 2) a topic that organizes practical guidance on the design scenarios and data architectures that may require the tuning of additional server properties.
Understanding how Analysis Services uses memory – Making the best performance decisions about memory utilization requires understanding how the Analysis Services server manages memory overall as well as how it handles the memory demands of processing and querying operations.
Optimizing memory usage – Optimizing memory usage requires applying a series of techniques to detect whether you have sufficient memory resources and to identify those configuration properties that impact memory resource utilization and overall performance.
Understanding how Analysis Services uses CPU resources – Making the best performance decisions about CPU utilization requires understanding how the Analysis Services server uses CPU resources overall as well as how it handles the CPU demands of processing and querying operations.
Optimizing CPU usage – Optimizing CPU usage requires applying a series of techniques to detect whether you have sufficient processor resources and to identify those configuration properties that impact CPU resource utilization and overall performance.
Understanding how Analysis Services uses disk resources – Making the best performance decisions about disk resource utilization requires understanding how the Analysis Services server uses disk resources overall as well as how it handles the disk resource demands of processing and querying operations.
Optimizing disk usage – Optimizing disk usage requires applying a series of techniques to detect whether you have sufficient disk resources and to identify those configuration properties that impact disk resource utilization and overall performance.
Understanding how Analysis Services uses memory
Analysis Services 2005 introduces a new memory architecture that allocates and manages memory in a more efficient manner than previous versions of Analysis Services where the memory management of dimensions and other objects placed limits on querying and processing performance. The primary goal of memory management in Analysis Service 2005 is to effectively utilize available memory while balancing the competing demands of processing and querying operations.
To help you gain some familiarity with the distinct memory demands of these two operations, following is a high-level overview of how Analysis Services 2005 uses memory during processing and querying:
- Querying—During querying, memory is used at various stages of query execution to satisfy query requests. To promote fast data retrieval, the Storage Engine cache is used to store measure group data. To promote fast calculation evaluation, the Query Execution Engine cache is used to store calculation results. To efficiently retrieve dimensions, dimension data is paged into memory as needed by queries, rather than being loaded into memory at server startup, as in prior versions of Analysis Services. To improve query performance, it is essential to have sufficient memory available to cache data results, calculation results, and as-needed dimension data.
- Processing—During processing, memory is used to temporarily store, index, and aggregate data before writing to disk. Each processing job requests a specific amount of memory from the Analysis Services memory governor. If sufficient memory is not available to perform the job, the job is blocked. To ensure that processing proceeds in an efficient manner, it is important to verify that there is enough memory available to successfully complete all processing jobs and to optimize the calculation of aggregations in memory.
Given the distinct memory demands of querying and processing, it is important to not only understand how each operation impacts memory usage, but it is also important to understand how the Analysis Services server manages memory across all server operations. The sections that follow describe the memory management techniques of the Analysis Services server as well as how it handles the specific demands of querying and processing
Memory management
To effectively understand Analysis Services memory management techniques, you must first consider the maximum amount of memory that Analysis Services can address. Analysis Services relies on Microsoft Windows virtual memory for its memory page pool. The amount of memory it can address depends on the version of SQL Server that you are using:
- For SQL Server 2005 (32-bit), the maximum amount of virtual memory that an Analysis Services process can address is 3 gigabytes (GB). By default, an Analysis Services process can only address 2 GB; however it is possible to enable Analysis Services to address 3 GB. For guidelines on how to optimize the addressable memory of Analysis Services, see Increasing available memory.
- SQL Server 2005 (64-bit) is not limited by a 3-GB virtual address space limit, enabling the 64-bit version of Analysis Services to use as much address space as it needs. This applies to both IA64 and X64 architectures.
To perform server operations, Analysis Services requests allocations of memory from the Windows operating system, and then returns that memory to the Windows operating system when the allocated memory is no longer needed. Analysis Services manages the amount of memory allocated to the server by using a memory range that is defined by two server properties: Memory\TotalMemoryLimit and Memory\LowMemoryLimit.
- Memory\TotalMemoryLimit represents the upper limit of memory that the server uses to manage all Analysis Services operations. If Memory\TotalMemoryLimit is set to a value between 0 and 100, it is interpreted as a percentage of total physical memory. If the property is set to a value above 100, Analysis Services interprets it as an absolute memory value in bytes. The default value for Memory\TotalMemoryLimit is 80, which translates to 80% of the amount of physical memory of the server.
Note that this property does not define a hard limit on the amount of memory that Analysis Services uses. Rather, it is a soft limit that is used to identify situations where the server is experiencing memory pressure. For some operations, such as processing, if Analysis Services requires additional memory beyond the value of Memory\TotalMemoryLimit, the Analysis Services server attempts to reserve that memory regardless of the value of the property.
- Memory\LowMemoryLimit represents the lower limit of memory that the server uses to manage all Analysis Services operations. Like the Memory\TotalMemoryLimit property, a value between 0 and 100 is interpreted as a percentage of total physical memory. If the property is set to a value above 100, Analysis Services interprets it as an absolute memory value in bytes.
The default value for the Memory\LowMemoryLimit property is 75, which translates to 75% of the amount of physical memory on the Analysis Services server.
Analysis Services uses these memory range settings to manage how memory is allocated and used at various levels of memory pressure. When the server experiences elevated levels of memory pressure, Analysis Services uses a set of cleaner threads, one cleaner thread per logical processor, to control the amount of memory allocated to various operations. Depending on the amount of memory pressure, the cleaner threads are activated in parallel to shrink memory as needed. The cleaner threads clean memory according to three general levels of memory pressure:
- No Memory Pressure—If the memory used by Analysis Services is below the value set in the Memory\LowMemoryLimit property, the cleaner does nothing.
- Some Memory Pressure—If the memory used by Analysis Services is between the values set in the Memory\LowMemoryLimit and the Memory\TotalMemoryLimit properties, the cleaner begins to clean memory using a cost/benefit algorithm. For more information on how the cleaner shrinks memory, see Shrinkable vs. non-shrinkable memory.
- High Memory Pressure—If the memory used by Analysis Services is above the value set in the Memory\TotalMemoryLimit property, the cleaner cleans until the memory used by Analysis Services reaches the Memory\TotalMemoryLimit. When the memory used by Analysis Services exceeds the Memory\TotalMemoryLimit, the server goes into an aggressive mode where it cleans everything that it can. If the memory used is mostly non-shrinkable (more information on non-shrinkable memory is included in the next section), and cannot be purged, Analysis Services detects that the cleaner was unable to clean much. If it is in this aggressive mode of cleaning, it tries to cancel active requests. When this point is reached, you may see poor query performance, out of memory errors in the event log, and slow connection times.
Shrinkable vs. non-shrinkable memory
Analysis Services divides memory into two primary categories: shrinkable memory and non-shrinkable memory as displayed in Figure 30.
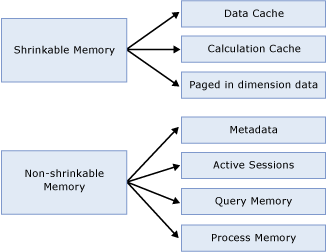
Figure 30 Shrinkable vs. non-shrinkable memory
When the cleaner is activated, it begins evicting elements of shrinkable memory, based on a cost/benefit algorithm that takes into account a variety of factors, including how frequently the entry is used, the amount of resources required to resolve the entries, and how much space is consumed by related entries. Shrinkable memory elements include the following:
- Cached Results—Cached results include the Storage Engine data cache and Query Execution Engine calculation cache. As stated earlier in this document, the Storage Engine data cache contains measure group data and the Query Execution Calculation Engine cache contains calculation results. While both caches can help improve query response times, the data cache provides the most benefit to query performance by storing data that has been cached from disk. In situations of memory pressure, the cleaner shrinks the memory used for cached results. With this in mind, it is a good practice to monitor the usage of memory so that you can minimize the scenarios where elevated levels of memory pressure force the removal of cached results. For more information on how to monitor memory pressure, see Monitoring memory management.
- Paged in dimension data—Dimension data is paged in from the dimension stores as needed. The paged-in data is kept in memory until the cleaner is under memory pressure to remove it. Note that this is different behavior than previous versions of Analysis Services where all dimension data was resident in memory.
- Expired Sessions—Idle client sessions that have exceeded a longevity threshold are removed by the cleaner based on the level of memory pressure. Several server properties work together to manage the longevity of idle sessions. For more information on how to evaluate these properties, see Monitoring the timeout of idle sessions.
Non-shrinkable memory elements are not impacted by the Analysis Services cleaner. Non-shrinkable memory includes the following components:
- Metadata For each Analysis Services database, metadata is initialized and loaded into memory on demand. Metadata includes the definition of all objects in the database (not the data elements). The more objects in your database (including cubes, measure groups, partitions, and dimensions) and the more databases that you have on a given server, the larger the metadata overhead in memory. Note that this overhead is generally not large for most implementations. However, you can experience significant overhead if your Analysis Services server contains hundreds of databases with tens or hundreds of objects per database, such as in hosted solutions. For more information on how to monitor metadata overheard, see Minimizing metadata overhead.
- Active Sessions—For each active session, calculated members, named sets, connections, and other associated session information is retained as non-shrinkable memory.
- Query Memory and Process Memory—Analysis Services reserves specific areas of memory for temporary use during querying and processing. During the execution of a query, for example, memory may be used to materialize data sets such as during the cross joining of data. During processing, memory is used to temporarily store, index, and aggregate data before it are written to disk. These memory elements are non-shrinkable because they are only needed to complete a specific server operation. As soon as the operation is over, these elements are removed from memory.
Memory demands during querying
During querying, memory is primarily used to store cached results in the data and calculation caches. As stated previously, of the two caches, the one that provides the most significant performance benefit is the data cache. When Analysis Services first starts, the data cache is empty. Until the data cache is loaded with data from queries, Analysis Services must resolve user queries by using data stored on disk, either by scanning the fact data or by using aggregations. Once these queries are loaded into the data cache, they remain there until the cleaner thread removes them or the cache is flushed during measure group or partition processing.
You can often increase query responsiveness by preloading data into the data cache by executing a generalized set of representative user queries. This process is called cache warming. While cache warming can be a useful technique, cache warming should not be used as a substitute for designing and calculating an appropriate set of aggregations. For more information on cache warming, see Warming the data cache.
Memory demands during processing
During processing, memory is required to temporarily store fact data and aggregations prior to writing them to disk.
Processing Fact data
Processing uses a double-buffered scheme to read and process fact records from the source database. Analysis Services populates an initial buffer from the relational database, and then populates a second buffer from the initial buffer where the data is sorted, indexed, and written to the partition file in segments. Each segment consists of 65,536 rows; the number of bytes in each segment varies based on the size of each row.
The OLAP\Process\BufferMemoryLimit property controls the amount of memory that is used per processing job to store and cache data coming from a relational data source. This setting along with OLAP\Process\BufferRecordLimit determines the number of rows that can be processed in the buffers. The OLAP\Process\BufferMemoryLimit setting is interpreted as a percentage of total physical memory if the value is less than 100, or an absolute value of bytes if the value is greater than 100. The default value is 60, which indicates that a maximum of 60% of the total physical memory can be used. For most deployments, the default value of OLAP\Process\BufferMemoryLimit provides sufficient processing performance. For more information on scenarios where it may be appropriate to change the value of this property, see Tuning memory for partition processing.
Building Aggregations
Analysis Services uses memory during the building of aggregations. Each partition has its own aggregation buffer space limit. Two properties control the size of the aggregation buffer:
- OLAP\Process\AggregationMemoryLimitMax is a server property that controls the maximum amount of memory that can be used for aggregation processing per partition processing job. This value is interpreted as a percentage of total memory if the value is less than 100, or an absolute value of bytes if the value is greater than 100. The default value is 80, which indicates that a maximum of 80% of the total physical memory can be used for aggregation processing.
- OLAP\Process\AggregationMemoryLimitMin is a server property that controls the minimum amount of memory that can be used for aggregation processing per partition processing job. This value is interpreted as a percentage of total memory if the value is less than 100, or an absolute value of bytes if the value is greater than 100. The default value is 10, which indicates that a minimum of 10% of the total physical memory will be used for aggregation processing
For a given partition, all aggregations are calculated at once. As a general best practice, it is a good idea to verify that all aggregations can fit into memory during creation; otherwise temporary files are used, which can slow down processing although the impact on performance is not as significant as in prior versions of Analysis Services. For more information on how to monitor the usage of temporary files, see Tuning memory for partition processing.
Optimizing memory usage
Optimizing memory usage for querying and processing operations requires supplying the server with adequate memory and verifying that the memory management properties are configured properly for your server environment. This section contains a summary of the guidelines that can help you optimize the memory usage of Analysis Services.
Increasing available memory
If you have one or more large or complex cubes and are using SQL Server 2005 (32-bit), use Windows Advanced Server® or Datacenter Server with SQL Server 2005 Enterprise Edition (or SQL Server 2005 Developer Edition) to enable Analysis Services to address up to 3 GB of memory. Otherwise, the maximum amount of memory that Analysis Services can address is 2 GB.
To enable Analysis Services to address more than 2 GB of physical memory with either of these editions, enable the Application Memory Tuning feature of Windows. To accomplish this, use the /3GB switch in the boot.ini file If you set the /3GB switch in the boot.ini file, the server should have at least 4 GB of memory to ensure that the Windows operating system also has sufficient memory for system services. If you run other applications on the server, you must factor in their memory requirements as well.
If you have one or more very large and complex cubes and your Analysis Services memory needs cannot be met within the 3-GB address space, SQL Server 2005 (64-bit) allows the Analysis Services process to access more than 3 GB of memory. You may also want to consider SQL Server 2005 (64-bit) in design scenarios where you have many partitions that you need to process in parallel or large dimensions that require a large amount of memory to process.
If you cannot add additional physical memory to increase performance, increasing the size of the paging files on the Analysis Services server can prevent out–of-memory errors when the amount of virtual memory allocated exceeds the amount of physical memory on the Analysis Services server.
Monitoring memory management
Given that the Memory\TotalMemoryLimit and Memory\LowMemoryLimit
properties are percentages by default, they dynamically reflect the amount of physical memory on the server, even if you add new memory to the server. Using these default percentages is beneficial in deployments where Analysis Services is the only application running on your server.
If Analysis Services is installed in a shared application environment, such as if you have Analysis Services installed on the same machine as SQL Server, consider assigning static values to these properties as opposed to percentages in order to constrain Analysis Services memory usage. In shared application environments, it is also a good idea to constrain how other applications on the server use memory.
When modifying these properties, it is a good practice to keep the difference between the Memory\LowMemoryLimit and Memory\TotalMemoryLimit is at least five percent, so that the cleaner can smoothly transition across different levels of memory pressure.
You can monitor the memory management of the Analysis Services server by using the following performance counters displayed in Table 3.
Table 3 Memory management performance counters
|
Performance counter name
|
Definition
|
|
MSAS 2005:Memory\Memory Limit Low KB
|
Displays the Memory\LowMemoryLimit from the configuration file
|
|
MSAS 2005:Memory\Memory Limit High KB
|
Displays the Memory\TotalMemoryLimit from the configuration file.
|
|
MSAS 2005:Memory\Memory Usage KB
|
Displays the memory usage of the server process. This is the value that is compared to Memory\LowMemoryLimit and Memory\TotalMemoryLimit. Note that the value of this performance counter is the same value displayed by the Process\Private Bytes performance counter.
|
|
MSAS 2005:Memory\Cleaner Balance/sec
|
Shows how many times the current memory usage is compared against the settings. Memory usage is checked every 500ms, so the counter will trend towards 2 with slight deviations when the system is under high stress.
|
|
MSAS 2005:Memory\Cleaner Memory nonshrinkable KB
|
Displays the amount of memory, in KB, non subject to purging by the background cleaner.
|
|
MSAS 2005:Memory\Cleaner Memory shrinkable KB
|
Displays the amount of memory, in KB, subject to purging by the background cleaner.
|
|
MSAS 2005:Memory\Cleaner Memory KB
|
Displays the amount of memory, in KB, known to the background cleaner. (Cleaner memory shrinkable + Cleaner memory non-shrinkable.) Note that this counter is calculated from internal accounting information so there may be some small deviation from the memory reported by the operating system.
|
Minimizing metadata overhead
For each database, metadata is initialized and loaded into non-shrinkable memory. Once loaded into memory, it is not subject to purging by the cleaner thread.
To monitor the metadata overhead for each database
- Restart the Analysis Services server.
- Note the starting value of the MSAS 2005:Memory\Memory Usage KB performance counter.
- Perform an operation that forces metadata initialization of a database, such as iterating over the list of objects in AMO browser sample application, or issuing a backup command on the database.
- After the operation has completed, note the ending value of MSAS 2005:Memory\Memory Usage KB. The difference between the starting value and the ending value represents the memory overhead of the database.
For each database, you should see memory growth proportional to the number of databases you initialize. If you notice that a large amount of your server memory is associated with metadata overhead, you may want consider whether you can take steps to reduce the memory overhead of a given database. The best way to do this is to re-examine the design of the cube. An excessive number of dimensions attributes or partitions can increase the metadata overhead. Where possible you should follow the design best practices outlined in Optimizing the dimension design and Reducing attribute overhead.
Monitoring the timeout of idle sessions
Client sessions are managed in memory. In general, there is a one-to-one relationship between connections and sessions. While each connection consumes approximately 32 KB of memory, the amount of memory a given session consumes depends on the queries and calculations performed in that session. You can monitor the current number of user sessions and connections by using the MSAS 2005:Connection\Current
connections and MSAS 2005:Connection\Current
user sessions performance counters to evaluate the connection and session demands on your system.
As stated earlier, active sessions consume non-shrinkable memory, whereas expired sessions consume shrinkable memory. Two main properties determine when a session expires:
- The MinIdleSessionTimeout is the threshold of idle time in seconds after which the server can destroy a session based on the level of memory pressure. The MinIdleSessionTimeout is set to 2,700 seconds (45 minutes). This means that a session must be idle for 45 minutes before it is considered an expired session that the cleaner can remove when memory pressure thresholds are exceeded.
- The MaxIdleSessionTimeout is the time in seconds after which the server forcibly destroys an idle session regardless of memory pressure. By default, the MaxIdleSessionTimeout is set to zero seconds, meaning that the idle session is never forcibly removed by this setting.
In addition to the properties that manage expired sessions, there are properties that manage the longevity of sessions that lose their connection. A connectionless session is called an orphaned session.
- The IdleOrphanSessionTimeout is a server property of that controls the timeout of connection-less sessions. By default this property is set to 120 seconds (three minutes), meaning that if a session loses its connection and a reconnection is not made within 120 seconds, the Analysis Services server forcibly destroys this session.
- IdleConnectionTimeout controls the timeout of connections that have not been used for a specified amount of time. By default, this property is set to zero seconds. This means that the connection never times out. However, given that the connection cannot exist outside of a session, any idle connection will be cleaned up whenever its session is destroyed.
For most scenarios, these default settings provide adequate server management of sessions. However, there may be scenarios where you want finer-grained session management. For example, you may want to alter these settings according to the level amount of memory pressure that the Analysis Services server is experiencing. During busy periods of elevated memory pressure, you may want to destroy idle sessions after 15 minutes. At times when the server is not busy, you want the idle sessions to be destroyed after 45 minutes. To accomplish this, set the MinIdleSessionTimeout property to 900 seconds (15 minutes) and the MaxIdleSessionTimeout to 2,700 seconds.
Note that before changing these properties, it is important to understand how your client application manages sessions and connections. Some client applications, for example, have their own timeout mechanisms for connections and sessions that are managed independently of Analysis Services.
Tuning memory for partition processing
Tuning memory for partition processing involves three general techniques:
- Modifying the OLAP\Process\BufferMemoryLimit property as appropriate.
- Verifying that sufficient memory is available for building aggregations.
- Splitting up processing jobs in memory-constrained environments.
Modifying the OLAP\Process\BufferMemoryLimit property as appropriate
OLAP\Process\BufferMemoryLimit determines the size of the fact data buffers using during partition processing. While the default value of the OLAP\Process\BufferMemoryLimit is sufficient for many deployments, you may find it useful to alter the property in the following scenarios:
- If the granularity of your measure group is more summarized than the relational source fact table, generally speaking you may want to consider increasing the size of the buffers to facilitate data grouping. For example, if the source data has a granularity of day and the measure group has a granularity of month, Analysis Services must group the daily data by month before writing to disk. This grouping only occurs within a single buffer and it is flushed to disk once it is full. By increasing the size of the buffer, you decrease the number of times that the buffers are swapped to disk and also decrease the size of the fact data on disk, which can also improve query performance.
- If the OLAP measure group is of the same granularity as the source relational fact table, you may benefit from using smaller buffers. When the relational fact table and OLAP measure group are at roughly the same level of detail, there is no need to group the data, because all rows remain distinct and cannot be aggregated. In this scenario, assigning smaller buffers is helpful, allowing you to execute more processing jobs in parallel.
Verifying that sufficient memory is available for building aggregations
During processing, the aggregation buffer determines the amount of memory that is available to build aggregations for a given partition. If the aggregation buffer is too small, Analysis Services supplements the aggregation buffer with temporary files. Temporary files are created in the TempDir folder when memory is filled and data is sorted and written to disk. When all necessary files are created, they are merged together to the final destination. Using temporary files can potentially result in some performance degradation during processing; however, the impact is generally not significant given that the operation is simply an external disk sort. Note that this behavior is different than in previous versions of Analysis Services.
To monitor any temporary files used during processing, review the MSAS 2005:Proc Aggregations\Temp file bytes written/sec or the MSAS 2005:Proc Aggregations\Temp file rows written/sec performance counters.
In addition, when processing multiple partitions in parallel or processing an entire cube in a single transaction, you must ensure that the total memory required does not exceed the Memory\TotalMemoryLimit property. If Analysis Services reaches the Memory\TotalMemoryLimit
during processing, it does not allow the aggregation buffer to grow and may cause temporary files to be used during aggregation processing. Furthermore, if you have insufficient virtual address space for these simultaneous operations, you may receive out-of-memory errors. If you have insufficient physical memory, memory paging will occur. If processing in parallel and you have limited resources, consider doing less in parallel.
Splitting up processing jobs in memory-constrained environments
During partition processing in memory-constrained environments, you may encounter a scenario where a ProcessFull operation on a measure group or partition cannot proceed due to limited memory resources. What is happening in this scenario is that the Process job requests an estimated amount of memory to complete the total ProcessFull operation. If the Analysis Services memory governor cannot secure enough memory for the job, the job can either fail or block other jobs as it waits for more memory to become available. As an alternative to performing a ProcessFull, you can split the processing operation into two steps by performing two operations serially: ProcessData and ProcessIndexes. In this scenario, the memory request will be smaller for each sequential operation and is less likely to exceed the limits of the system resources.
Warming the data cache
During querying, memory is primarily used to store cached results in the data and calculation caches. To optimize the benefits of caching, you can often increase query responsiveness by preloading data into the data cache by executing a generalized set of representative user queries. This process is called cache warming. To do this, you can create an application that executes a set of generalized queries to simulate typical user activity in order to expedite the process of populating the query results cache. For example, if you determine that users are querying by month and by product, you can create a set of queries that request data by product and by month. If you run this query whenever you start Analysis Services, or process the measure group or one of its partitions, this will pre-load the query results cache with data used to resolve these queries before users submit these types of query. This technique substantially improves Analysis Services response times to user queries that were anticipated by this set of queries.
To determine a set of generalized queries, you can use the Analysis Services query log to determine the dimension attributes typically queried by user queries. You can use an application, such as a Microsoft Excel macro, or a script file to warm the cache whenever you have performed an operation that flushes the query results cache. For example, this application could be executed automatically at the end of the cube processing step.
Running this application under an identifiable user name enables you to exclude that user name from the Usage-Based Optimization Wizard’s processing and avoid designing aggregations for the queries submitted by the cache warming application.
When testing the effectiveness of different cache-warming queries, you should empty the query results cache between each test to ensure the validity of your testing. You can empty the results cache using a simple XMLA command such as the following:
<Batch
xmlns=“http://schemas.microsoft.com/analysisservices/2003/engine“>
<ClearCache>
<Object>
<DatabaseID>Adventure Works DW</DatabaseID>
</Object>
</ClearCache>
</Batch>
This example XMLA command clears the cache for the Adventure Works DW database. To execute the ClearCache statement, you can either manually run the XMLA statement in SQL Server Management Studio or use the ASCMD tool command-line utility to execute any XMLA script.
Understanding how Analysis Services uses CPU resources
Analysis Services uses processor resources for both querying and processing. Increasing the number and speed of processors can significantly improve processing performance and, for cubes with a large number of users, improve query responsiveness as well.
Job architecture
Analysis Services uses a centralized job architecture to implement querying and processing operations. A job itself is a generic unit of processing or querying work. A job can have multiple levels of nested child jobs depending on the complexity of the request.
During processing operations, for example, a job is created for the object that you are processing, such as a dimension. A dimension job can then spawn several child jobs that process the attributes in the dimension. During querying, jobs are used to retrieve fact data and aggregations from the partition to satisfy query requests. For example, if you have a query that accesses multiple partitions, a parent job is generated for the query itself along with one or more child jobs per partition.
Generally speaking, executing more jobs in parallel has a positive impact on performance as long as you have enough processor resources to effectively handle the concurrent operations as well as sufficient memory and disk resources. The maximum number of jobs that can execute in parallel across all server operations (including both processing and querying) is determined by the CoordinatorExecutionMode property.
- A negative value for CoordinatorExecutionMode specifies the maximum number of parallel jobs that can start per processor.
- A value of zero enables the server to automatically determine the maximum number of parallel operations, based on the workload and available system resources.
- A positive value specifies an absolute number of parallel jobs that can start per server.
The default value for the CoordinatorExecutionMode is -4, which indicates that four jobs will be started in parallel per processor. This value is sufficient for most server environments. If you want to increase the level of parallelism in your server, you can increase the value of this property either by increasing the number of jobs per processor or by setting the property to an absolute value. While this globally increases the number of jobs that can execute in parallel, CoordinatorExecutionMode is not the only property that influences parallel operations. You must also consider the impact of other global settings such as the MaxThreads server properties that determine the maximum number of querying or processing threads that can execute in parallel. In addition, at a more granular level, for a given processing operation, you can specify the maximum number of processing tasks that can execute in parallel using the MaxParallel command. These settings are discussed in more detail in the sections that follow.
Thread pools
To effectively manage processor resources for both querying and processing operations, Analysis Services 2005 uses two thread pools:
- Querying thread pool—The querying thread pool controls the worker threads used by the Query Execution Engine to satisfy query requests. One thread from the querying pool is used per concurrent query. The minimum number of threads from the querying pool is determined by the value of the ThreadPool\Query\MinThreads property; its default setting is 1. The maximum number of worker threads maintained in the querying thread pool is determined by the value of ThreadPool\Query\MaxThreads; its default setting is 10.
- Processing thread pool—The processing thread pool controls the worker threads used by the Storage Engine during processing operations. The processing thread pool is also used during querying to control the threads used by the Storage Engine to retrieve data from disk. The ThreadPool\Process\MinThreads property determines the minimum number of processing threads that can be maintained at a given time. The default value of this property is 1. The ThreadPool\Process\MaxThreads property determines the maximum number of processing threads that can be maintained at a given time. The default value of this property is 64.
For scenarios on when these values should be changed, see Optimizing CPU usage. Before you modify these properties, it is useful to examine how these threads are used during querying and processing.
Processor demands during querying
During querying, to manage client connections, Analysis Services uses a listener thread to broker requests and create new server connections as needed. To satisfy query requests, the listener thread manages worker threads in the querying thread pool and the processing thread pool, assigns worker threads to specific requests, initiates new worker threads if there are not enough active worker threads in a given pool, and terminates idle worker threads as needed.
To satisfy a query request, the thread pools are used as follows:
- Worker threads from the query pool check the data and calculation caches respectively for any data and/or calculations pertinent to a client request.
- If necessary, worker threads from the processing pool are allocated to retrieve data from disk.
- Once data is retrieved, worker threads from the querying pool store the results in the query cache to resolve future queries.
- Worker threads from the querying pool perform necessary calculations and use a calculation cache to store calculation results.
The more threads that are available to satisfy queries, the more queries that you can execute in parallel. This is especially important in scenarios where you have a large number of users issuing queries. For more information on how to optimize processor resources during querying, see Maximize parallelism during querying.
Processor demands during processing
Where possible, Analysis Services naturally performs all processing operations in parallel. For every processing operation, you can specify the parallelism of the Analysis Services object by using the MaxParallel processing command. By default, the MaxParallel command is configured to Let the server decide, which is interpreted as unlimited parallelism, constrained only by hardware and server workload. For more information on how you can change this setting, see Maximize parallelism during processing.
Of all of the processing operations, partitions place the largest demands on processor resources. Each partition is processed in two stages and each stage is a multithreaded activity.
- During the first stage of processing a partition, Analysis Services populates an initial buffer from the relational database, populates a second buffer from the initial buffer, and then writes segments to the partition file. Analysis Services utilizes multiple threads for this stage, which execute asynchronously. This means that while data is being added to the initial buffer, data is being moved from the initial buffer into the second buffer and sorted into segments. When a segment is complete, it is written to the partition file. Processor usage during this first phase depends on the speed of the data transfer from the relational tables. Generally this stage is not particularly processor-intensive, using less than one processor. Rather, this stage is generally limited by the speed of retrieving data from the relational database. The maximum size of the buffer used to store the source data is determined by the OLAP\Process\BufferMemoryLimit and OLAP\Process\BufferRecordLimit server
properties. In some scenarios, it can be beneficial to modify these settings to improve processing performance. For more information on these properties, see Memory demands during processing.
- During the second stage, Analysis Services creates and computes aggregations for the data. Analysis Services utilizes multiple threads for this stage, executing these tasks asynchronously. These threads read the fact data into an aggregation buffer. If sufficient memory is allocated to the aggregation buffer, these aggregations are calculated entirely in memory. As stated previously in the Memory demands during processing section, if Analysis Services does not have sufficient memory to calculate aggregations, Analysis Services uses temporary files to supplement the aggregation buffer. This stage can be processor-intensive; Analysis Services takes advantage of multiple processors if they are available.
Optimizing CPU usage
While adding additional processor resources can improve the overall performance of Analysis Services, use the following guidelines to optimize the usage of processor resources.
Maximize parallelism during querying
As stated in the Thread pools section, Threadpool\Query\MaxThreads determines the maximum number of worker threads maintained in the querying thread pool. The default value of this property is 10. For servers that have more than one processor, to increase parallelism during querying, consider modifying Threadpool\Query\MaxThreads to be a number dependent on the number of server processors. A general recommendation is to set the Threadpool\Query\MaxThreads to a value of less than or equal to 2 times the number of processors on the server. For example, if you have an eight-processor machine, the general guideline is to set this value to no more than 16. In practical terms, increasing Threadpool\Query\MaxThreads will not significantly increase the performance of a given query. Rather, the benefit of increasing this property is that you can increase the number of queries that can be serviced concurrently.
Since querying also involves retrieving data from partitions, to improve parallel query operations, you must also consider the maximum threads available in the processing pool as specified by the Threadpool\Process\MaxThreads property. By default, this property has a value of 64. While partitions are naturally queried in parallel, when you have many queries that require data from multiple partitions, you can enhance data retrieval by changing the Threadpool\Process\MaxThreads property. When modifying this property, a general recommendation is to set the Threadpool\Process\MaxThreads to a value of less than or equal to 10 times the number of processors on the machine. For example, if you have an eight-processor server, the general guideline is setting this value to no more than 80. Note even though the default value is 64, if you have fewer than eight processors on a given server, you do not need to reduce the default value to throttle parallel operations. As you consider the scenarios for changing the Threadpool\Process\MaxThreads property, remember that changing this setting impacts the processing thread pool for both querying and processing. For more information on how this property specifically impacts processing operations, see Maximizing parallelism during processing.
While modifying the Threadpool\Process\MaxThreads and Threadpool\Query\MaxThreads properties can increase parallelism during querying, you must also take into account the additional impact of the CoordinatorExecutionMode. Consider the following example. If you have a four-processor server and you accept the default CoordinatorExecutionMode setting of
-4, a total of 16 jobs can be executed at one time across all server operations. So if ten queries are executed in parallel and require a total of 20 jobs, only 16 jobs can launch at a given time (assuming that no processing operations are being performed at that time). When the job threshold has been reached, subsequent jobs wait in a queue until a new job can be created. Therefore, if the number of jobs is the bottleneck to the operation, increasing the thread counts may not necessarily improve overall performance.
In practical terms, the balancing of jobs and threads can be tricky. If you want to increase parallelism, it is important to assess your greatest bottleneck to parallelism, such as the number of concurrent jobs and/or the number of concurrent threads, or both. To help you determine this, it is helpful to monitor the following performance counters:
Maximize parallelism during processing
For processing operations, you can use the following mechanisms to maximize parallelism:
- CoordinatorExecutionMode—As stated earlier, this server-wide property controls the number of parallel operations across the server. If you are performing processing at the same time as querying, it is a good practice to increase this value.
- Threadpool\Process\MaxThreads—Also discussed earlier in this section, this server-wide property increases the number of threads that can be used to support parallel processing operations.
-
MaxParallel processing command—Rather than globally specifying the number of parallel operations for a given Analysis Services instance, for every processing operation, you can specify the maximum number of tasks that can operate in parallel. In many scenarios, this is the most common setting that is used to affect parallelism. You can specify the MaxParallel command in two ways: the Maximum parallel tasks option in the processing user interface or a custom XMLA script.
-
Maximum parallel tasks option—When you launch a processing operation from SQL Server Management Studio or Business Intelligence Development Studio, you can specify the Maximum parallel tasks option to change the level of parallelism for a given processing operation as displayed in Figure 31. The default value of this setting is Let the server decide,
which is interpreted as unlimited parallelism, constrained only by hardware and server workload. The drop-down list displays a list of suggested values but you can specify any value. If you increase this value to increase parallelism, be wary of setting the property too high. Performing too many parallel operations at once can be counterproductive if it causes context switching and degrades performance.

Figure 31 Maximum parallel tasks setting
- Custom XMLA script —As an alternative to specifying the MaxParallel command in the user interface, you can write a custom XMLA script to perform a processing operation and use the MaxParallel element to control the number of parallel operations within the XMLA script.
When processing multiple partitions in parallel, use the guidelines displayed in Table 4 for the number of partitions that can be processed in parallel according to the number of processors. These guidelines were taken from processing tests performed using Project REAL cubes.
Table 4 Partition processing guidelines
|
# of Processors
|
# of Partitions to be processed in parallel
|
|
4
|
2 – 4
|
|
8
|
4 – 8
|
|
16
|
6 – 16
|
Note that the actual number of partitions that can be processed in parallel depends on the querying workload and design scenario. For example, if you are performing querying and processing at the same time, you may want to decrease the number of partitions processed in parallel in order to keep some free resources for querying. Alternatively, if your design contains SQL queries with many complex joins, your parallel partition processing performance could be limited by the source database. If the source database is on the same machine as Analysis Services, you may see memory and CPU interactions that limit of the benefits of parallel operations. In fact, with too much parallelism you can overload the RDBMS so much that it leads to timeout errors, which cause processing to fail. By default, the maximum number of concurrent connections, and thus queries, for a data source is limited to ten. This can be changed by altering the Maximum Number of Connections setting of the data source properties in either Business Intelligence Development Studio or SQL Server Management Studio.
To help you monitor the number of partitions processing in parallel, you can review the MSAS 2005:Processing\Rows read/sec performance counter. Generally you should expect this counter to display 40,000–60,000 rows per second for one partition. If your partition contains complex SQL joins or hundreds of source columns, you are likely to see a lower rate. Additionally, you can monitor the number of threads being used during processing by using the MSAS 2005: Threads\Processing pool busy threads performance counter. You can also view jobs that are waiting to execute by using the MSAS 2005: Threads\Processing pool job queue length performance counter.
Note that when you perform parallel processing of any object, all parallel operations are committed in one transaction. In other words, it is not possible to perform a parallel execution and then commit each transaction as it progresses. While this is not specifically a performance issue, it does impact your processing progress. If you encounter any errors during processing, the entire transaction rolls back.
Use sufficient memory
The Optimizing memory usage section describes techniques to ensure that Analysis Services has sufficient memory to perform querying and processing operations. Ensuring that Analysis Services has sufficient memory can also impact Analysis Services usage of processor resources. If the Analysis Services server has sufficient memory, the Windows operating system will not need to page memory from disk. Paging reduces processing performance and query responsiveness.
Use a load-balancing cluster
If your performance bottleneck is processor utilization on a single system as a result of a multi-user query workload, you can increase query performance by using a cluster of Analysis Services servers to service query requests. Requests can be load balanced across two Analysis Services servers, or across a larger number of Analysis Services servers to support a large number of concurrent users (this is called a server farm). Load-balancing clusters generally scale linearly. Both Microsoft and third-party vendors provide cluster solutions. The Microsoft load-balancing solution is Network Load Balancing (NLB), which is a feature of the Windows Server operating system. With NLB, you can create an NLB cluster of Analysis Services servers running in multiple host mode. When an NLB cluster of Analysis Services servers is running in multiple host mode, incoming requests are load balanced among the Analysis Services servers. When you use a load-balancing cluster, be aware that the data caches on each of the servers in the load-balancing cluster will be different, resulting in differences in query response times from query to query by the same client.
A load-balancing cluster can also be used to ensure availability in the event that a single Analysis Services server fails. An additional option for increasing performance with a load-balancing cluster is to distribute processing tasks to an offline server. When new data has been processed on the offline server, you can update the Analysis Services servers in the load-balancing cluster by using Analysis Services database synchronization.
If your users submit a lot of queries that require fact data scans, a load-balancing cluster may be a good solution. For example, queries that may require a large number of fact data scans include wide queries (such as top count or medians), and random queries against very complex cubes where the probability of hitting an aggregation is very low.
However, a load-balancing cluster is generally not needed to increase Analysis Services performance if aggregations are being used to resolve most queries. In other words, concentrate on good aggregation and partitioning design first. In addition, a load-balancing cluster does not solve your performance problem if processing is the bottleneck or if you are trying to improve an individual query from a single user. Note that one restriction to using a load-balancing cluster is the inability to use writeback, because there is no single server to which to write back the data.
Understanding how Analysis Services uses disk resources
Analysis Services uses disk I/O resources for both querying and processing. Increasing the speed of your disks, spreading the I/O across multiple disks, and using multiple controllers, can significantly improve processing performance. These steps also significantly improve query responsiveness when Analysis Services is required to perform fact data scans. If you have a large number of queries that require fact data scans, Analysis Services can become constrained by insufficient disk I/O when there is not enough memory to support the file system cache in addition to Analysis Services memory usage.
Disk resource demands during processing
As stated previously in the Memory demands during processing section, during processing, the aggregation buffer determines the amount of memory that is available to build aggregations for a given partition. If the aggregation buffer is too small, Analysis Services uses temporary files. Temporary files are created in the TempDir folder when memory is filled and data is sorted and written to disk. When all necessary files are created, they are merged together to the final destination. Using temporary files can result in some performance degradation during processing; however, the impact is generally not significant given that the operation is simply an external disk sort. Note that this behavior is different than previous versions of Analysis Services. To monitor any temporary files used during processing, review the MSAS 2005:Proc Aggregations\Temp file bytes written/sec or the MSAS 2005:Proc Aggregations\Temp file rows written/sec performance counters.
Disk resource demands during querying
During querying, Analysis Services may request arbitrary parts of the data set, depending on user query patterns. When scanning a single partition, the I/Os are essentially sequential, except that large chunks may be skipped because the indexes may indicate that they aren’t needed. If commonly used portions of the cube (particularly the mapping files) fit in the file system cache, the Windows operating system may satisfy the I/O requests from memory rather than generating physical I/O. With large cubes, using a 64-bit version of the Microsoft Windows Server 2003 family increases the amount of memory that the operating system can use to cache Analysis Services requests. With sufficient memory, much of the cube can be stored in the file system cache.
Optimizing disk usage
While increasing disk I/O capacity can significantly improve the overall performance of Analysis Services, there are several steps you can take to use existing disk I/O more effectively. This section contains guidelines to help you optimize disk usage of Analysis Services.
Using sufficient memory
The Optimizing memory usage section describes techniques to ensure that Analysis Services has sufficient memory to perform querying and processing operations. Ensuring that Analysis Services has sufficient memory can also impact Analysis Services usage of disk resources. For example, if there is not enough memory to complete processing operations, Analysis Services uses temporary files, generating disk I/O.
If you cannot add sufficient physical memory to avoid memory paging, consider creating multiple paging files on different drives to spread disk I/O across multiple drives when memory paging is required.
Optimizing file locations
The following techniques can help you to optimize the data files and temporary files used during processing:
• Place the Analysis Services data files on a fast disk subsystem.
The location of the data files is determined by the DataDir server property. To optimize disk access for querying and processing, place the Analysis Services Data folder on a dedicated disk subsystem (RAID 5, RAID 1+0, or RAID 0+1).
• If temporary files are used during processing, optimize temporary file disk I/O.
The default location of the temporary files created during aggregation processing is controlled by the TempDir property. If a temporary file is used, you can increase processing performance by placing this temporary folder on a fast disk subsystem (such as RAID 0 or RAID 1+0) that is separate from the data disk.
Disabling unnecessary logging
Flight Recorder provides a mechanism to record Analysis Services server activity into a short-term log. Flight Recorder provides a great deal of benefit when you are trying to troubleshoot specific querying and processing problems; however, it introduces a certain amount of I/O overheard. If you are in a production environment and you do not require Flight Recorder capabilities, you can disable its logging and remove the I/O overhead. The server property that controls whether Flight Recorder is enabled is the Log\Flight Recorder\Enabled property. By default, this property is set to true.
Conclusion
For more information:
http://www.microsoft.com/technet/prodtechnol/sql/2005/technologies/ssasvcs.mspx
Did this paper help you? Please give us your feedback. On a scale of 1 (poor) to 5 (excellent), how would you rate this paper?
Appendix A – For More Information
The following white papers might be of interest.
Appendix B – Partition Storage Modes
Each Analysis Services partition can be assigned a different storage mode that specifies where fact data and aggregations are stored. This appendix describes the various storage modes that Analysis Services provides: multidimensional OLAP (termed MOLAP), hybrid OLAP (HOLAP), and relational OLAP (ROLAP). Generally speaking. MOLAP provides the fastest query performance; however, it typically involves some degree of data latency.
In scenarios where you require near real-time data refreshes and the superior query performance of MOLAP, Analysis Services provides proactive caching. Proactive caching is an advanced feature that requires a special set of performance tuning techniques to ensure that it is applied effectively. For more information on the performance considerations of using proactive caching, see Near real-time data refreshes in this white paper.
Multidimensional OLAP (MOLAP)
MOLAP partitions store aggregations and a copy of the source data (fact and dimension data) in a multidimensional structure on the Analysis Services server. All partitions are stored on the Analysis Services server.
Analysis Services responds to queries faster with MOLAP than with any other storage mode for the following reasons:
- Compression—Analysis Services compresses the source fact data and its aggregations to approximately 30 percent of the size of the same data stored in a relational database. The actual compression ratio varies based on a variety of factors, such as the number of duplicate keys and bit encoding algorithms. This reduction in storage size enables Analysis Services to resolve a query against fact data or aggregations stored in a MOLAP structure much faster than against data and aggregations stored in a relational structure because the size of the physical data being retrieved from the hard disk is smaller.
- Multidimensional data structures—Analysis Services uses native multidimensional data structures to quickly find the fact data or aggregations. With ROLAP and HOLAP partitions, Analysis Services relies on the relational engine to perform potentially large table joins against fact data stored in the relational database to resolve some or all queries. Large table joins against relational structures take longer to resolve than similar queries against the MOLAP structures.
- Data in a single service—MOLAP partitions are generally stored on a single Analysis Services server, with the relational database frequently stored on a server separate from the Analysis Services server. When the relational database is stored on a separate server and partitions are stored using ROLAP or HOLAP, Analysis Services must query across the network whenever it needs to access the relational tables to resolve a query. The impact of querying across the network depends on the performance characteristics of the network itself. Even when the relational database is placed on the same server as Analysis Services, inter-process calls and the associated context switching are required to retrieve relational data. With a MOLAP partition, calls to the relational database, whether local or over the network, do not occur during querying.
Hybrid OLAP (HOLAP)
HOLAP partitions store aggregations in a multidimensional structure on the Analysis Services server, but leave fact data in the original relational database. As a result, whenever Analysis Services needs to resolve a query against fact data stored in a HOLAP partition, Analysis Services must query the relational database directly rather than querying a multidimensional structure stored on the Analysis Services server. Furthermore, Analysis Services must rely on the relational engine to execute these queries. Querying the relational database is slower than querying a MOLAP partition because of the large table joins generally required.
Some administrators choose HOLAP because HOLAP appears to require less total storage space while yielding excellent query performance for many queries. However, these apparent justifications for using HOLAP storage option are negated by the likelihood of excessive aggregations and additional indexes on relational tables.
- Excessive aggregations—Query responsiveness with HOLAP partitions relies on the existence of appropriate aggregations so that Analysis Services does not have to resolve queries against the fact table in the relational database. To ensure that a wide range of aggregations exists, administrators sometimes resort to generating excessive aggregations by increasing the performance improvement percentage in the Aggregation Design Wizard, or artificially increasing the partition row counts (and sometimes both). While these techniques increase the percentage of queries that Analysis Services can resolve using aggregations, there will always be some queries that can only be resolved against the fact data (remember the one-third rule). In addition, generating additional aggregations to improve query responsiveness comes at the cost of significantly longer processing times and increased storage requirements (which also negates the space savings).
- Additional indexes on relational tables—To ensure that the relational engine can quickly resolve queries that Analysis Services must resolve against the fact table in the relational database, administrators often add appropriate indexes to the fact and dimension tables. These additional indexes frequently require more space than MOLAP requires to store the entire cube. The addition of these indexes negates the apparent savings in disk space that is sometimes used to justify HOLAP. In addition, maintaining the indexes on the relational tables slows the relational engine when adding new data to the relational tables.
From a processing perspective, there is no significant difference in processing performance between MOLAP partitions and HOLAP partitions. In both cases, all fact data is read from the relational database, and aggregations are calculated. With MOLAP, Analysis Services writes the fact data into the MOLAP structure. With HOLAP, Analysis Services does not store fact data. This difference has minimal impact on processing performance, but can have a significant impact on query performance. Because HOLAP and MOLAP processing speeds are approximately the same and MOLAP query performance is superior, MOLAP is the optimum storage choice.
Relational OLAP (ROLAP)
ROLAP partitions store aggregations in the same relational database that stores the fact data. By default, ROLAP partitions store dimensions in MOLAP on the Analysis Services server, although the dimensions can also be stored using ROLAP in the relational database (for very large dimensions). Analysis Services must rely on the relational engine to resolve all queries against the relational tables, storing both fact data and aggregations. The sheer number of queries with large table joins in large or complex cubes frequently overwhelms the relational engine.
Given the slower query performance of ROLAP, the only situation in which ROLAP storage should be used is when you require reduced data latency and you cannot use proactive caching. For more information on proactive caching, see Near real-time data refreshes in this white paper. In this case, to minimize the performance cost with ROLAP, consider creating a small near real-time ROLAP partition and create all other partitions using MOLAP. Using MOLAP for the majority of the partitions in a near real-time OLAP solution allows you to optimize the query responsiveness of Analysis Services for most queries, while obtaining the benefits of real-time OLAP.
From a processing perspective, Analysis Services can store data, create MOLAP files, and calculate aggregations faster than a relational engine can create indexes and calculate aggregations. The primary reason the relational engine is slower is due to the large table joins that the relational engine must perform during the processing of a ROLAP partition. In addition, because the relational engine performs the actual processing tasks, competing demands for resources on the computer hosting the relational tables can negatively affect processing performance for a ROLAP partition.
Appendix C – Aggregation Utility
As a part of the Analysis Services 2005 Service Pack 2 samples, the Aggregation Utility is an advanced tool that complements the Aggregation Design Wizard and the Usage-Based Optimization Wizard by allowing you to create custom aggregation designs without using the aggregation design algorithm. This is useful in scenarios where you need to override the algorithm and create a specific set of aggregations to tune your query workload. Rather than relying on the cost/benefit analysis performed by the algorithm, you must decide which aggregations are going to be most effective to improve query performance without negatively impacting processing times.
Benefits of the Aggregation Utility
The Aggregation Utility enables you to complete the following tasks.
View and modify specific aggregations in an existing aggregation design.
Using the Aggregation Utility, you can view, add, delete, and change individual aggregations in existing designs. Once you build an aggregation design using the Aggregation Design Wizard or Usage-Based Optimization Wizard, you can use the utility to view the attributes that make up each aggregation. In addition, you have the ability to modify an individual aggregation by changing the attributes that participate in the aggregation.
Create new aggregation designs.
You can either create new aggregation designs by manually selecting the attributes for the aggregations, or by using the utility to build aggregations based on the query log. Note that the Aggregation Utility’s ability to build aggregations from the query log is very different than the functionality of the Usage-Based Optimization Wizard. Remember that the Usage-Based Optimization Wizard reads data from the query log and then uses the aggregation design algorithm to determine whether or not an aggregation should be built. While the Usage-Based Optimization Wizard gives greater consideration to the attributes contained in the query log, there is no absolute guarantee that they will be built.
When you use the Aggregation Utility to build new aggregations from the query log, you decide which aggregations provide the most benefit for your query performance without negatively impacting processing times. In other words, you are no longer relying on the aggregation design algorithm to select which aggregations are built. To help you make effective decisions, the utility enables you to optimize your design, including the ability to remove redundancy, eliminate duplicates, and remove large aggregations that are close to the size of the fact table.
Review whether aggregations are flexible or rigid.
A bonus of the Aggregation Utility is the ability to easily identify whether an aggregation is flexible or rigid. By default, aggregations are flexible. Remember that in a flexible aggregation, one or more attributes have flexible relationships while in a rigid aggregation, all attributes have rigid relationships. If you want change an aggregation from flexible to rigid, you must first change all of the necessary attribute relationships. Once you make these changes, you can use the utility to confirm that you have been successful as the aggregation will now be identified as rigid. Without the utility, you need to manually review the aggregation files in the operating system to determine whether they were flexible or rigid. For more information on rigid and flexible aggregations, see Evaluating rigid vs. flexible aggregations in this white paper.
How the Aggregation Utility organizes partitions
Using the Aggregation Utility, you can connect to an instance of Analysis Services and manage aggregation designs across all of the cubes and databases in that instance. For each measure group, the Aggregation Utility groups partitions by their aggregation designs. Figure 32 displays an example of this grouping.
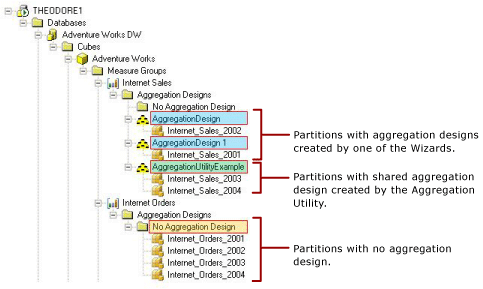
Figure 32 Aggregation display for the Internet Sales measure group
The partitions in Figure 32 are grouped as follows:
- Aggregation design created by a wizard—Aggregation designs created by the Aggregation Design Wizard or the Usage-Based Optimization Wizard are automatically named AggregationDesign, with an optional number suffix if more than one Wizard-created aggregation design exists per measure group. For example, in the Internet Sales measure group, the Internet_Sales_2002 partition has an aggregation design named AggregationDesign, and the Internet_Sales_2001 partition contains an aggregation design named AggregationDesign 1. Both AggregationDesign and AggregationDesign 1 were created by one of the wizards.
- Aggregation design created by the Aggregation Utility—The Internet_Sales_2003 and Internet_Sales_2004 partitions share an aggregation design, called AggregationUtilityExample. This aggregation design was created by the Aggregation Utility. The Aggregation Utility allows you to provide a custom name for each aggregation design.
- No Aggregation Design—For the Internet Orders measure group, none of the partitions in that measure group have an aggregation design yet.
How the Aggregation Utility works
The most common scenario for using the Aggregation Utility is to design aggregations based on a query log. Following is a list of steps to effectively use the Aggregation Utility to design new aggregations based on the query log.
To add new aggregations based on the query log
-
Perform pre-requisite set up tasks.
Before using the Aggregation Utility, you must configure Analysis Services query logging just as you would before you use the Usage-Based Optimization Wizard. As you set up query logging, pay close attention to configure an appropriate value for the QueryLogSampling property. The default value of this property is set to one out of every ten queries. Depending on your query workload, you may need to increase this value in order to collect a representative set of queries in the Analysis Services query log table. Obtaining a good sampling of queries is critical to effectively using the Aggregation Utility.
-
Add a new aggregation design based on a query log.
To extract data from the query log table, the Aggregation Utility provides a default query that returns a distinct list of datasets for a given partition. A dataset is the subcube that is used to satisfy query requests. An example of the default query is depicted in the query below. The values highlighted in yellow are placeholder values.
Select distinct dataset from OLAPQueryLog
Where MSOLAP_Database = DatabaseName and
MSOLAP_ObjectPath = MeasureGroupName
Generally speaking, it is a good idea to modify the default SQL statement to apply additional filters that restrict the records based on Duration or MSOLAP_User. For example, you may only return queries where the Duration > 30 seconds or MSOLAP_User = Joe.
In addition, whenever you add a new aggregation design by using the Aggregation Utility, it is a good idea to use a special naming convention to name the aggregation design as well as the aggregation prefix. This allows you to easily identify those aggregations that have been created by the utility. For example, when you use SQL Server Profiler to analyze the effectiveness of your aggregations, with easily recognizable names, you will be able to quickly identify those aggregations that have been created by the Aggregation Utility.
-
Eliminate redundant aggregations.
You can optimize a new aggregation design by eliminating redundant aggregations. Redundant aggregations are those aggregations that include one or more attributes in the same attribute relationship tree.
The aggregation highlighted in Figure 33 identifies an aggregation with attributes from two dimensions: Product and Time. From the product dimension, the aggregation includes the English Product Category Name
attribute. From the Time dimension, the aggregation includes the following attributes: English Month Name, Calendar Quarter, and Calendar Year. This is a redundant aggregation since English Month Name, Calendar Quarter, and Calendar Year are in the same attribute relationship tree.
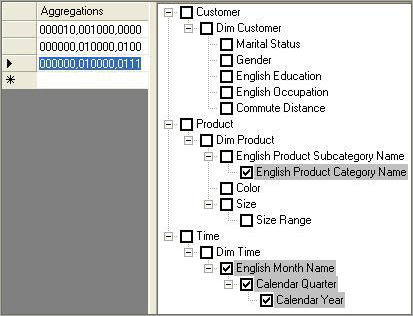
Figure 33 Redundant aggregation example
To remove the redundancy in this aggregation, use the Eliminate Redundancy option in the Aggregation Utility. Figure 34 displays the aggregation after the Eliminate Redundancy option is applied. The aggregation now only includes the English Month Name attribute from the Time dimension.
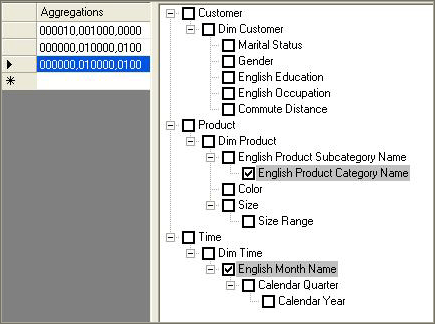
Figure 34 Aggregations with redundancy eliminated
-
Eliminate duplicate aggregations.
Duplicate aggregations are aggregations that include the exact same set of attributes. Continuing with example in Figure 34, note that the there are two identical aggregations for 0000000,010000,0100. This aggregation consists of the English Product Category
Name and English Month Name attributes. After the Eliminate Duplicates option is applied, the duplicated aggregation is removed and the updated aggregation design is presented in Figure 35.
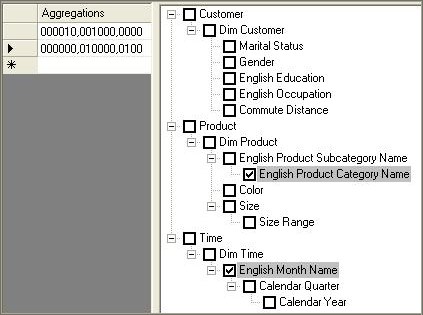
Figure 35 Aggregations with duplicates eliminated
-
Assign the aggregation design to a partition.
After you assign the aggregation design to one or more partitions, the utility displays the assigned partitions under the name of the new aggregation design, as displayed in Figure 32.
-
Save the measure group to SQL Server.
Your new aggregation design and partition assignment is not saved on the server until you perform an explicit save on the modified measure group. If you exit out of the utility and do not save, your changes will not be committed to the server.
-
Process the
partition.
Process the necessary measure group or partitions to build the aggregations for your new design. This operation needs to be performed outside of the Aggregation Utility using your normal processing techniques. Note that if you simply need to build aggregations, you can perform a ProcessIndexes operation on the appropriate measure group / partitions. For more information on ProcessIndexes, see Partition-processing commands.
-
Evaluate
the
aggregation size.
With the aggregations processed, you can use the Aggregation Utility to evaluate the relative size of each aggregation compared with the fact data for the partition. Using this information, you manually eliminate relatively large aggregations that take a long time to process and do not offer significant querying benefits. Remember that the aggregation design algorithm eliminates any aggregations that are greater than one third the size of the fact table. To apply similar logic, you can easily identify and delete any aggregations in your custom aggregation design that are significantly large.
-
Re-save to SQL Server and reprocess.
After you evaluate the aggregation size and remove any large aggregations, re-save the aggregation design and then reprocess the necessary partitions. For any subsequent changes that you make over time, always remember to re-save and reprocess.


 1
1





 Note:
Note: 
 You can see from the wireframe page that the Adventure Works Travel site supports some SharePoint functionality but not all of it. For example, some elements such as the Help button, Tree View, and Recycle Bin will be omitted from the UI. By making these decisions at the wireframe stage, developers do not have to build unnecessary functionality.
You can see from the wireframe page that the Adventure Works Travel site supports some SharePoint functionality but not all of it. For example, some elements such as the Help button, Tree View, and Recycle Bin will be omitted from the UI. By making these decisions at the wireframe stage, developers do not have to build unnecessary functionality. As you create the design comp, decide how to replicate the concepts in SharePoint. Figure 5 shows the same design comp with labels applied that highlight each functional area. Table 3 describes the functional areas.
As you create the design comp, decide how to replicate the concepts in SharePoint. Figure 5 shows the same design comp with labels applied that highlight each functional area. Table 3 describes the functional areas.
 Before converting an HTML design into a functional SharePoint site, test the design in as many browsers as possible. In addition to Internet Explorer, by installing Mozilla Firefox, Google Chrome, and Apple’s Safari for Windows, you can test a web design for many different browsing scenarios. Another option for testing in multiple browsers is to use
Before converting an HTML design into a functional SharePoint site, test the design in as many browsers as possible. In addition to Internet Explorer, by installing Mozilla Firefox, Google Chrome, and Apple’s Safari for Windows, you can test a web design for many different browsing scenarios. Another option for testing in multiple browsers is to use 


 From here, the page can be edited to include any content, including the subtitle, page content, and any Web Parts. In SharePoint Server 2010, Web Parts do not have to be added to Web Part zones; they can also be added to rich HTML content areas in publishing pages and wiki pages. Figure 11 shows the final page with all of the content from the HTML mockup added.
From here, the page can be edited to include any content, including the subtitle, page content, and any Web Parts. In SharePoint Server 2010, Web Parts do not have to be added to Web Part zones; they can also be added to rich HTML content areas in publishing pages and wiki pages. Figure 11 shows the final page with all of the content from the HTML mockup added. After all of the changes are finalized, just click the small Save icon at the top left of the ribbon or click Page, and then click Save & Close. If the publishing workflow is activated for the pages library, the page must be published and approved before end users will be able to see the new content.
After all of the changes are finalized, just click the small Save icon at the top left of the ribbon or click Page, and then click Save & Close. If the publishing workflow is activated for the pages library, the page must be published and approved before end users will be able to see the new content.


















